Lost in Translation: Latent Concept Misalignment in Text-to-Image Diffusion Models
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
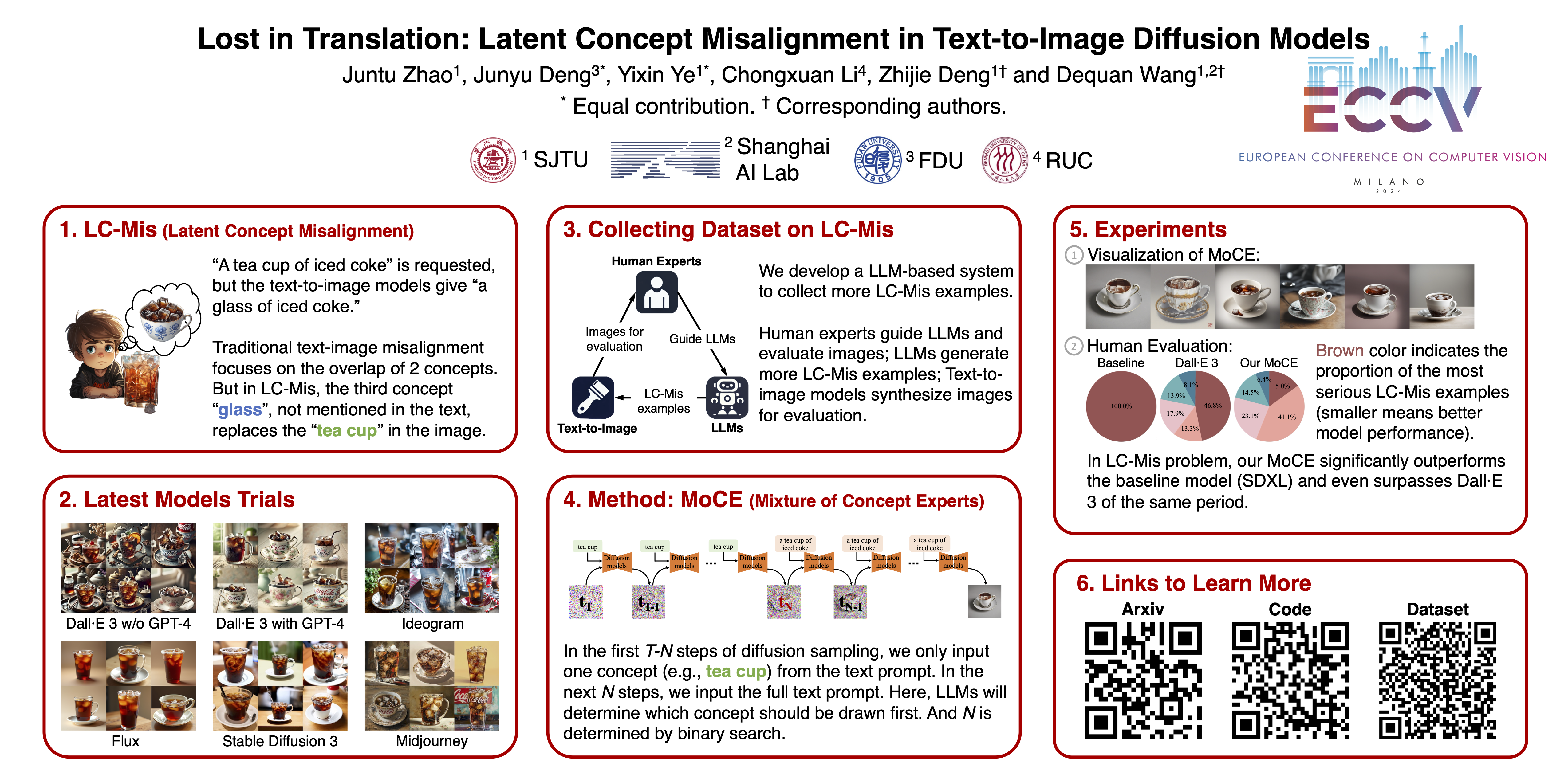
Advancements in text-to-image diffusion models have broadened extensive downstream practical applications, but such models often encounter misalignment issues between text and image. Taking the generation of a combination of two disentangled concepts as an example, say given the prompt “a tea cup of iced coke”, existing models usually generate a glass cup of iced coke because the iced coke usually co-occurs with the glass cup instead of the tea one during model training. The root of such misalignment is attributed to the confusion in the latent semantic space of text-to-image diffusion models, and hence we refer to the “a tea cup of iced coke” phenomenon as Latent Concept Misalignment (LC-Mis). We leverage large language models (LLMs) to thoroughly investigate the scope of LC-Mis, and develop an automated pipeline for aligning the latent semantics of diffusion models to text prompts. Empirical assessments confirm the effectiveness of our approach, substantially reducing LC-Mis errors and enhancing the robustness and versatility of text-to-image diffusion models. Our code and dataset have been available online for reference.