S-JEPA: A Joint Embedding Predictive Architecture for Skeletal Action Recognition
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
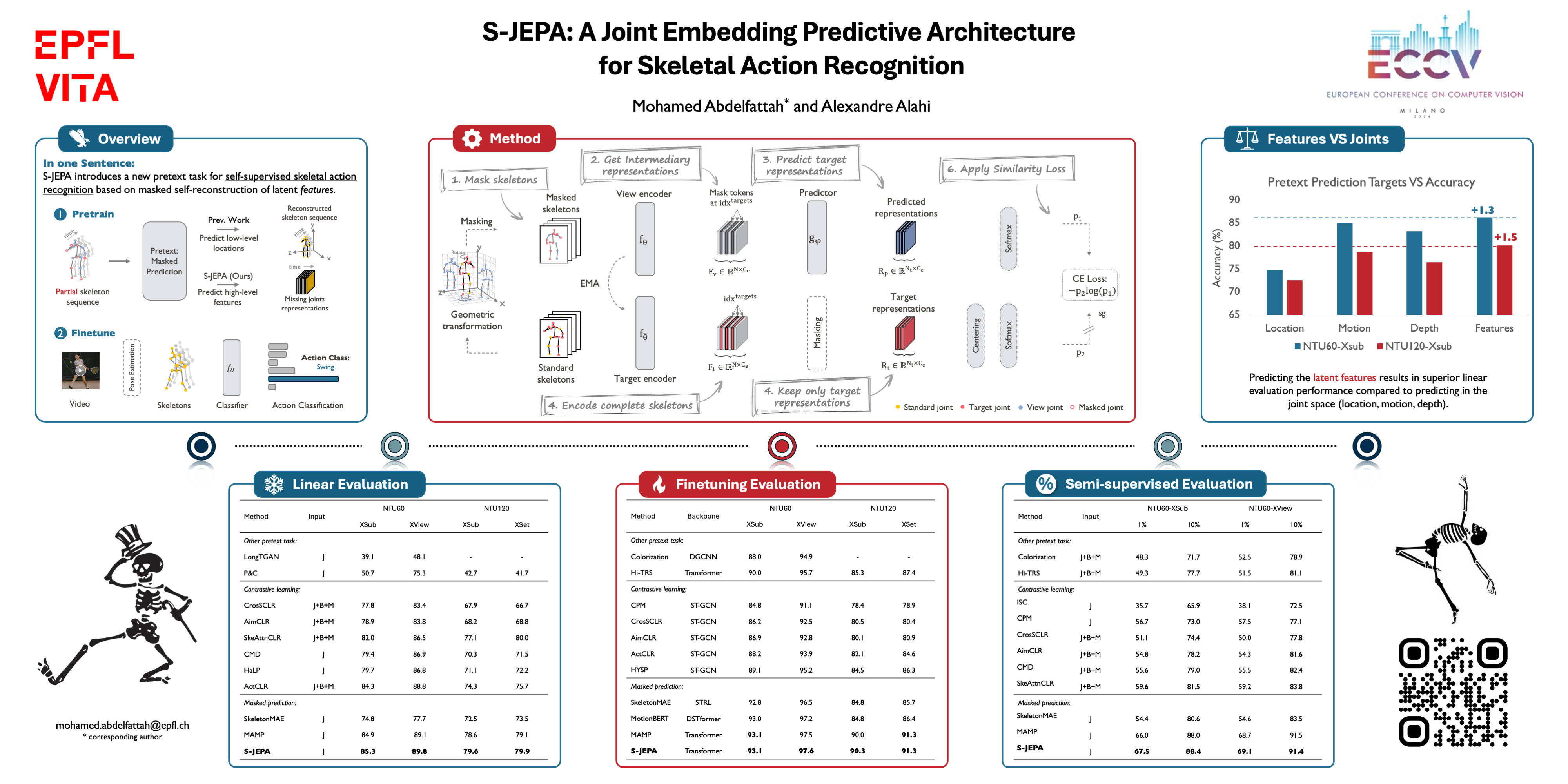
Masked self-reconstruction of joints has been shown to be a promising pretext task for self-supervised skeletal action recognition. However, this task focuses on predicting isolated, potentially noisy, joint coordinates, which results in inefficient utilization of the model capacity. In this paper, we introduce S-JEPA, Skeleton Joint Embedding Predictive Architecture, which uses a novel pretext task: Given a partial 2D skeleton sequence, our objective is to predict the latent representations of its 3D counterparts. Such representations serve as abstract prediction targets that direct the modelling power towards learning the high-level context and depth information, instead of unnecessary low-level details. To tackle the potential non-uniformity in these representations, we propose a simple centering operation that is found to benefit training stability, effectively leading to strong off-the-shelf action representations. Extensive experiments show that S-JEPA, combined with the vanilla transformer, outperforms previous state-of-the-art results on NTU60, NTU120, and PKU-MMD datasets. Codes will be available upon publication.