X-Former: Unifying Contrastive and Reconstruction Learning for MLLMs
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
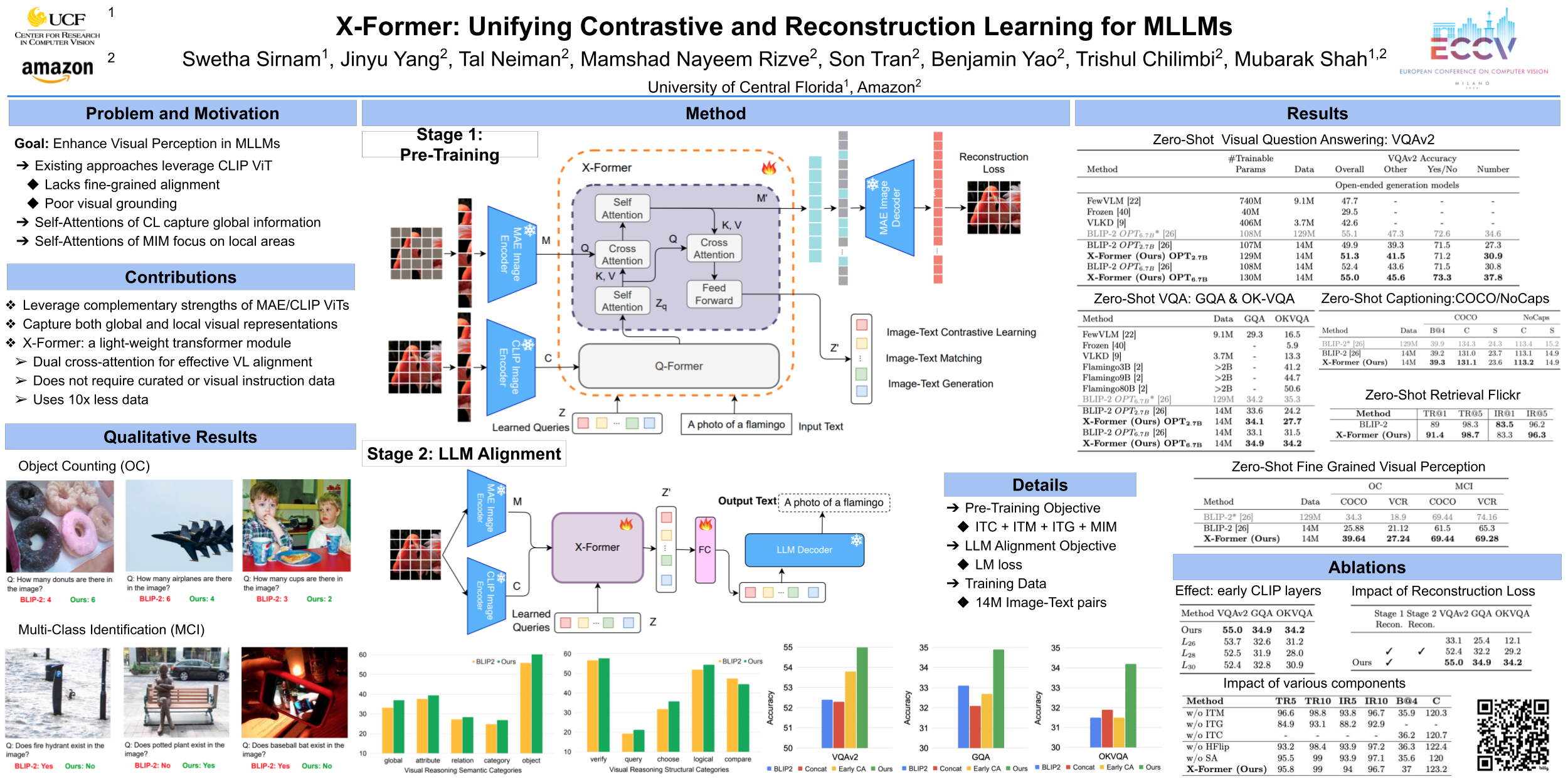
Recent advancements in Multimodal Large Language Models (MLLMs) have revolutionized the field of vision-language understanding by incorporating visual perceptioning capabilities into Large Language Models (LLMs). The prevailing trend in this field involves the utilization of a vision encoder derived from vision-language contrastive learning (CL), showing expertise in capturing overall representations while facing difficulties in capturing detailed local patterns. In this work, we focus on enhancing the visual representations for MLLMs by combining high-frequency and fine-grained representations, obtained through masked image modeling (MIM), with semantically-enriched low-frequency representations captured by CL. To achieve this goal, we introduce X-Former which is a lightweight transformer module designed to exploit the complementary strengths of CL and MIM through an innovative interaction mechanism. Specifically, X-Former first bootstraps vision-language representation learning and multimodal-to-multimodal generative learning from two frozen vision encoders, i.e., CLIP-ViT (CL-based) \cite{radford2021clip} and MAE-ViT (MIM-based) \cite{he2022mae}. It further bootstraps vision-to-language generative learning from a frozen LLM to ensure visual features from X-Former can be interpreted by the LLM. To demonstrate the effectiveness of our approach, we assess its performance on tasks demanding fine-grained visual understanding. Our extensive empirical evaluations indicate that X-Former excels in visual reasoning tasks encompassing both structural and semantic categories within the GQA dataset. Assessment on a fine-grained visual perception benchmark further confirms its superior capabilities in visual understanding.