NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image
{kind=link}
Abstract
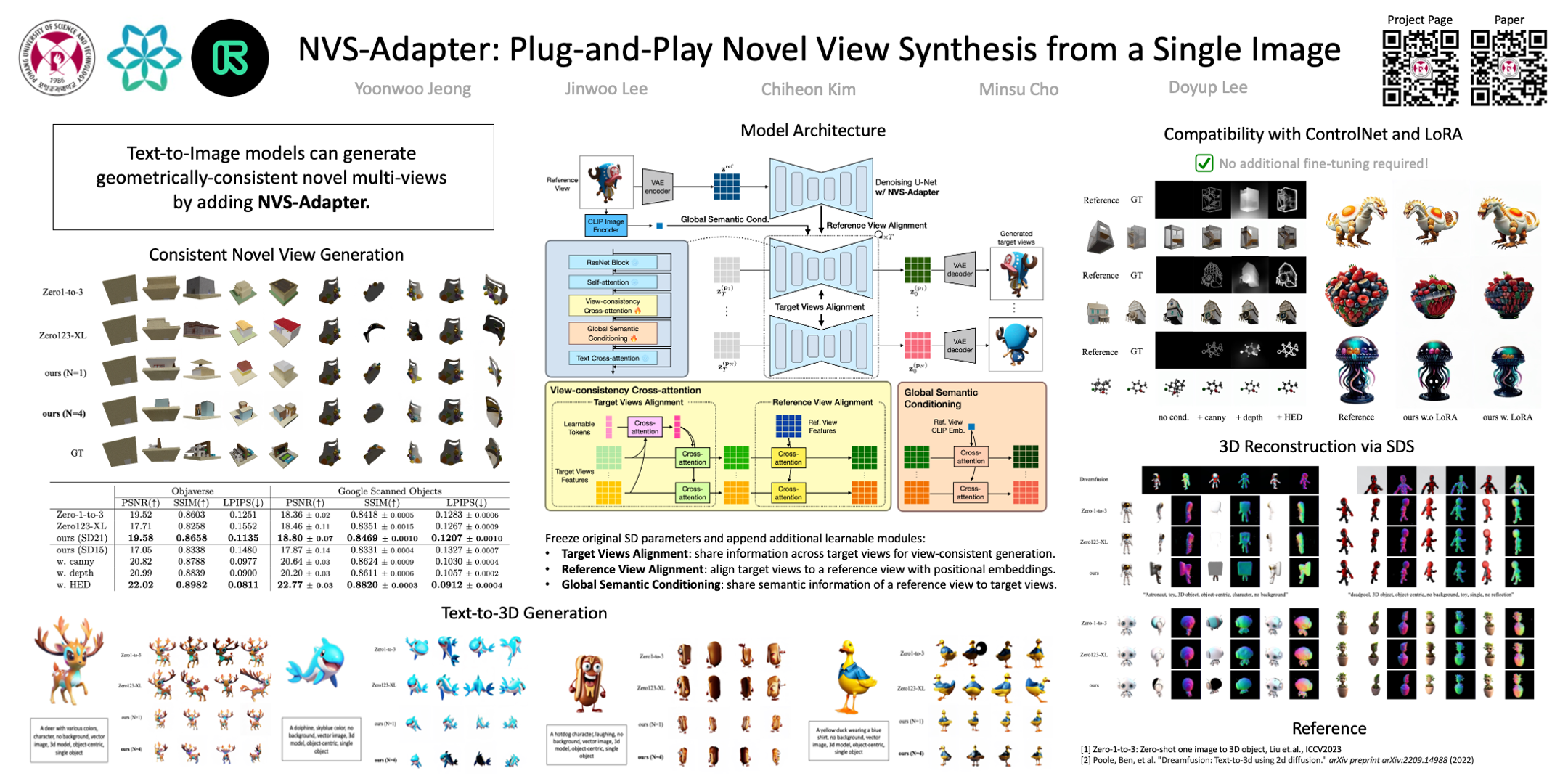
Recent advancements in Novel View Synthesis (NVS) from a single image have produced impressive results by leveraging the generation capabilities of pre-trained Text-to-Image (T2I) models. However, previous NVS approaches require extra optimization to use other plug-and-play image generation modules such as ControlNet and LoRA, as they fine-tune the T2I parameters. In this study, we propose an efficient plug-and-play adaptation module, NVS-Adapter, that is compatible with existing plug-and-play modules without extensive fine-tuning. We introduce target views and reference view alignment to improve the geometric consistency of multi-view predictions. Experimental results demonstrate the compatibility of our NVS-Adapter with existing plug-and-play modules. Moreover, our NVS-Adapter shows superior performance over state-of-the-art methods on NVS benchmarks although it does not fine-tune billions of parameters of the pre-trained T2I models.