DrivingDiffusion: Layout-Guided Multi-View Driving Scenarios Video Generation with Latent Diffusion Model
{kind=link}
Abstract
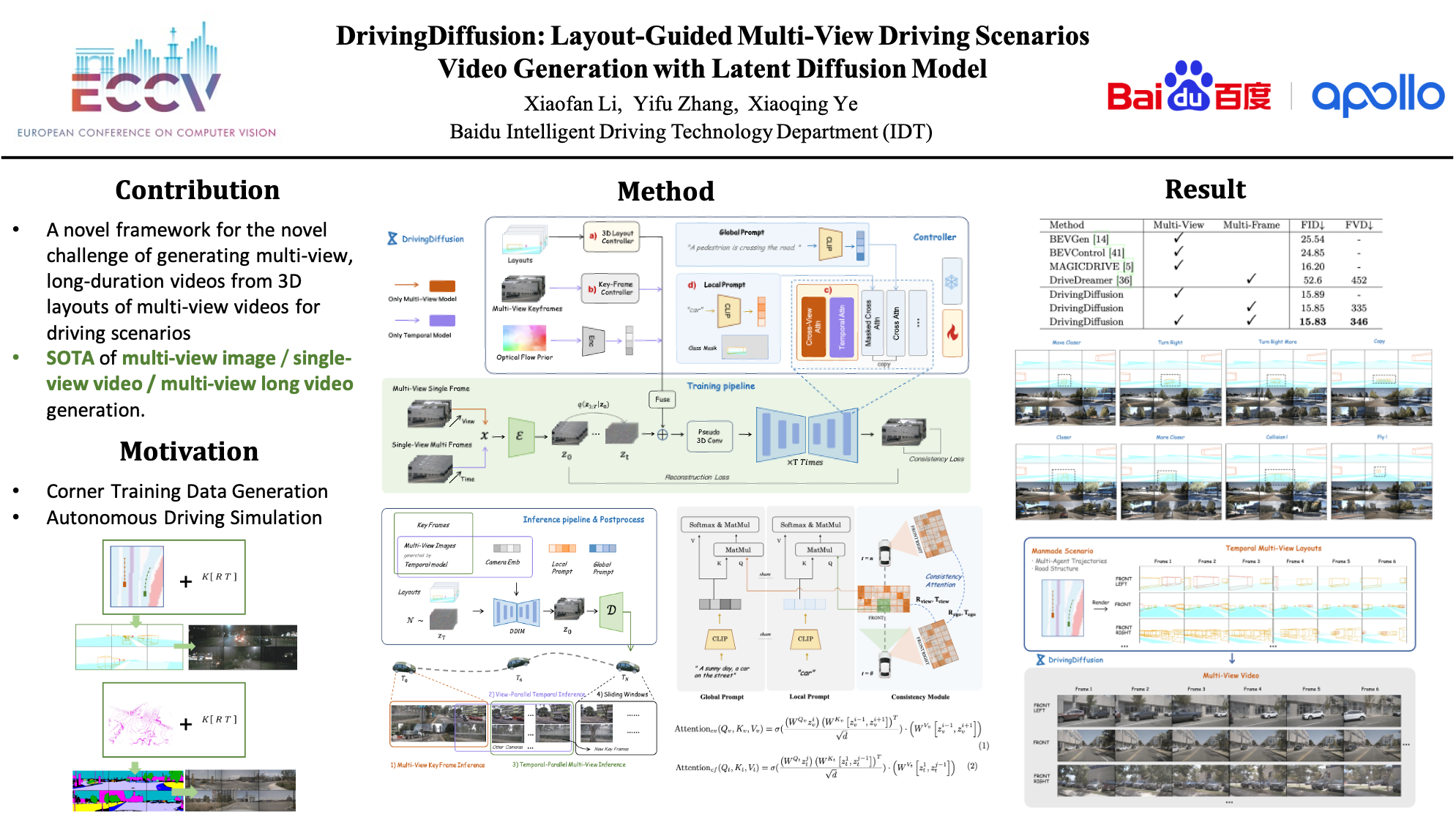
With the surge in autonomous driving technologies, the reliance on comprehensive and high-definition bird's-eye-view (BEV) representations has become paramount. This burgeoning need underscores the demand for extensive multi-view video datasets, meticulously annotated to facilitate advanced research and development. Nonetheless, the acquisition of such datasets is impeded by prohibitive costs associated with data collection and annotation. There are two challenges when synthesizing multi-view videos given a 3D layout: Generating multi-view videos involves handling both view and temporal dimensions. How to generate videos while ensuring cross-view consistency and cross-frame consistency? 2) How to ensure the precision of layout control and the quality of the generated instances? Addressing this critical bottleneck, we introduce a novel spatial-temporal consistent diffusion framework, DrivingDiffusion, engineered to synthesize realistic multi-view videos governed by 3D spatial layouts. DrivingDiffusion adeptly navigates the dual challenges of maintaining cross-view and cross-frame coherence, along with meeting the exacting standards of layout fidelity and visual quality. The framework operates through a tripartite methodology: initiating with the generation of multi-view single-frame images, followed by the synthesis of single-view videos across multiple cameras, and culminating with a post-processing phase. We corroborate the efficacy of DrivingDiffusion through rigorous quantitative and qualitative evaluations, demonstrating its potential to significantly enhance autonomous driving tasks without incurring additional costs.