TimeCraft: Navigate Weakly-Supervised Temporal Grounded Video Question Answering via Bi-directional Reasoning
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
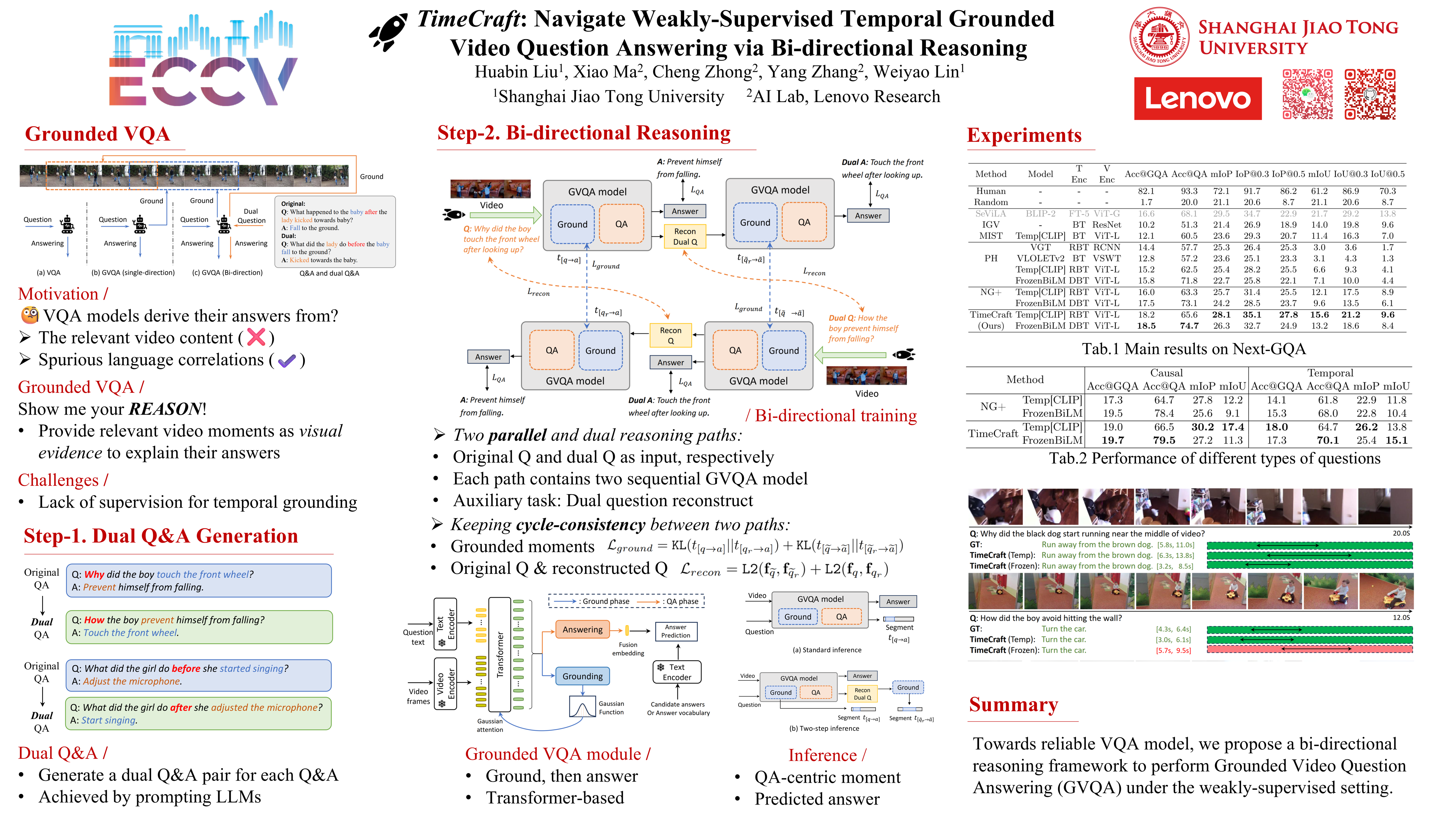
Video reasoning typically operates within the Video Question-Answering (VQA) paradigm, which demands that the models understand and reason about video content from temporal and causal perspectives. Traditional supervised VQA methods gain this capability through meticulously annotated QA datasets, while advanced visual-language models exhibit remarkable performance due to large-scale visual-text pretraining data. Nevertheless, due to potential language bias and spurious visual-text correlations in cross-modal learning, concerns about the reliability of their answers persist in real-world applications. In this paper, we focus on the grounded VQA task, which necessitates models to provide answers along with explicit visual evidence, i.e., certain video segments. As temporal annotation is not available during training, we propose a novel bi-directional reasoning framework to perform grounded VQA in a weakly-supervised setting. Specifically, our framework consists of two parallel but dual reasoning paths. They conduct temporal grounding and answering based on the video content, approaching it from two dual directions that are symmetrical in terms of temporal order or causal relationships. By constructing a cycle-consistency relationship between these two branches, the model is prompted to provide self-guidance supervision for both temporal grounding and answering. Experiments conducted on the Next-GQA and Env-QA datasets demonstrate that our framework achieves superior performance in grounded VQA and can provide reasonable temporal locations that validate the answers.