ReGround: Improving Textual and Spatial Grounding at No Cost
{kind=link}
Abstract
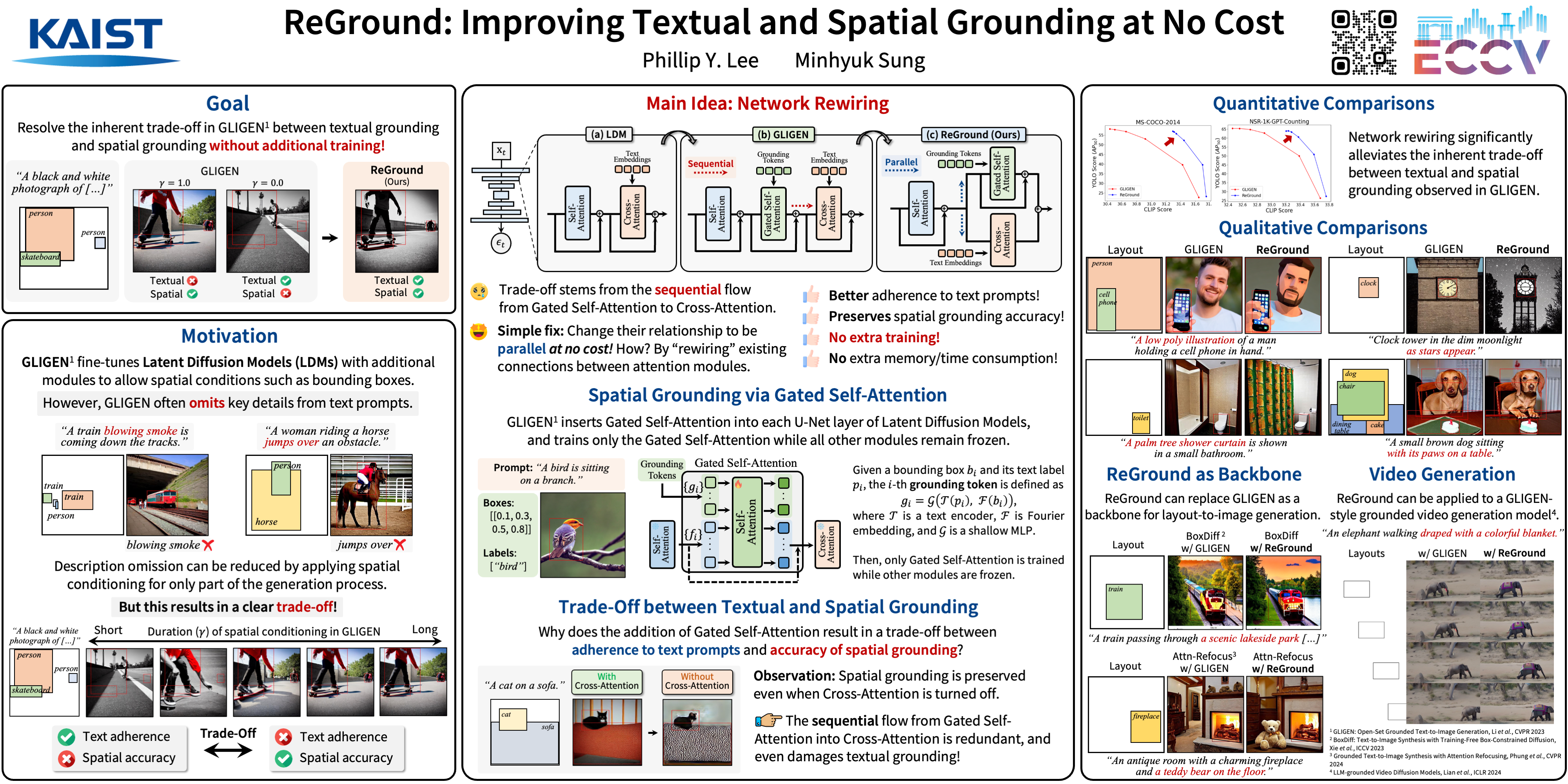
When an image generation process is guided by both a text prompt and spatial cues, such as a set of bounding boxes, do these elements work in harmony, or does one dominate the other? Our analysis of a pretrained image diffusion model that integrates gated self-attention into the U-Net reveals that spatial grounding often outweighs textual grounding due to the sequential flow from gated self-attention to cross-attention. We demonstrate that such bias can be significantly mitigated without sacrificing accuracy in either grounding by simply rewiring the network architecture, changing from sequential to parallel for gated self-attention and cross-attention. This surprisingly simple yet effective solution does not require any fine-tuning of the network but significantly reduces the trade-off between the two groundings. Our experiments demonstrate significant improvements from the original GLIGEN to the rewired version in the trade-off between textual grounding and spatial grounding.