FuseTeacher: Modality-fused Encoders are Strong Vision Supervisors
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
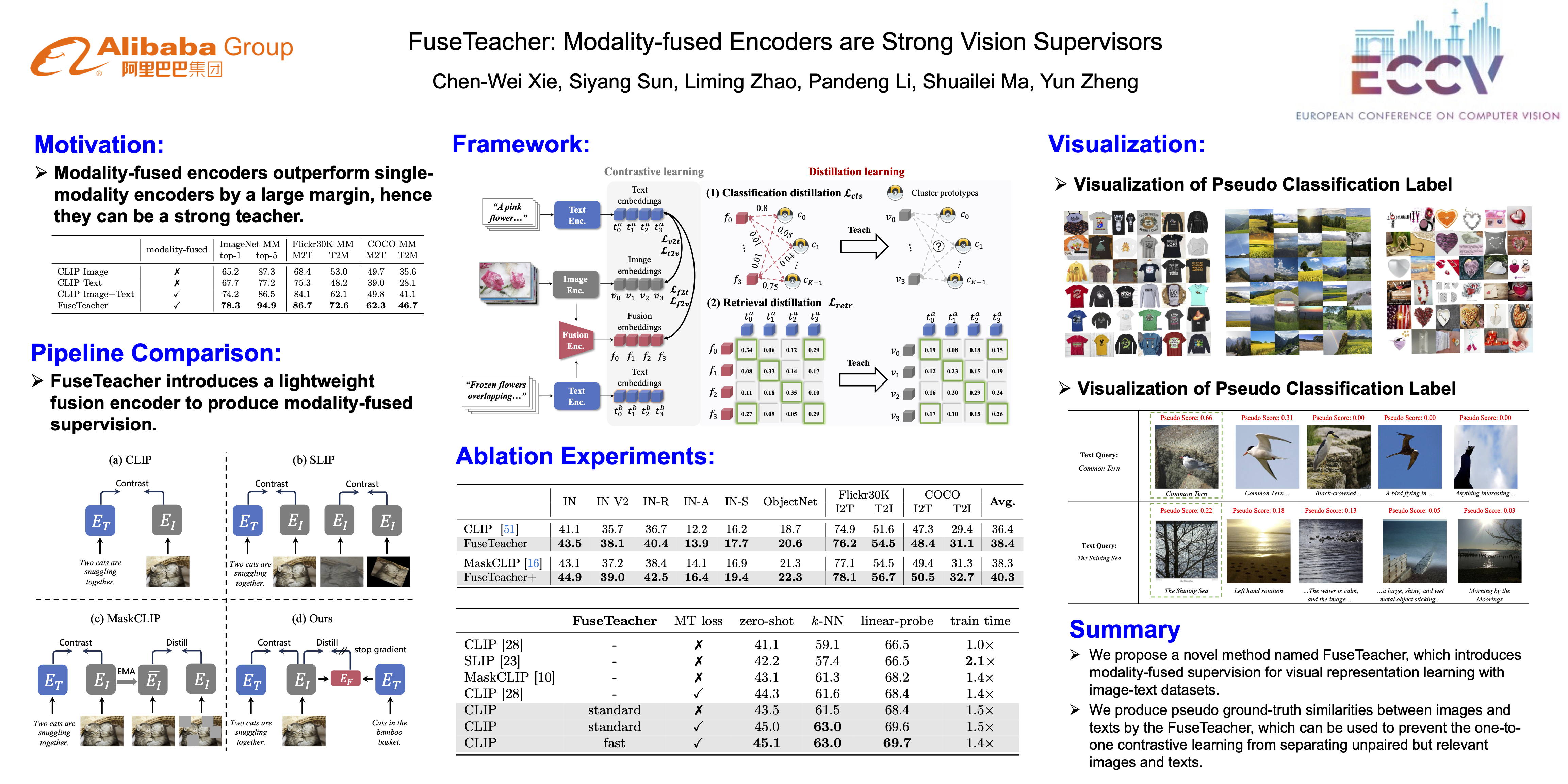
Learning visual representation with image-text datasets attracts a lot of attention in recent years. Existing approaches primarily rely on cross-modality supervision, and incorporate intra-modality supervision if necessary. They overlook the potential benefits of modality-fused supervision. Since modality-fused representation augments the image representation with textual information, we conjecture it is more discriminative and potential to be a strong teacher for visual representation learning. In this paper, we validate this hypothesis by experiments and propose a novel method FuseTeacher that learns visual representation by modality-fused supervision. Specifically, we introduce a fusion encoder that encodes image and text into a fusion representation. This representation can be utilized to supervise the visual representation learning in two distillation ways: (i) Classification Distillation: we cluster image-text pairs into K clusters using the fusion representation and assign each pair a soft cluster assignment, which is served as a pseudo classification label for supervising the image encoder. (ii) Retrieval Distillation: we calculate the similarities between the fusion representation and all text representations in the same batch. By using the similarity distribution as pseudo retrieval similarity between the corresponding image and all texts, we can prevent one-to-one contrastive learning from separating relevant but unpaired pairs. The FuseTeacher is compatible with existing language supervised visual representation learning methods. Experimental results demonstrate that it is able to bring significant improvements and achieves state-of-the-art methods on various datasets. Our code, datasets and pre-trained models will be released.