3DFG-PIFu: 3D Feature Grids for Human Digitization from Sparse Views
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
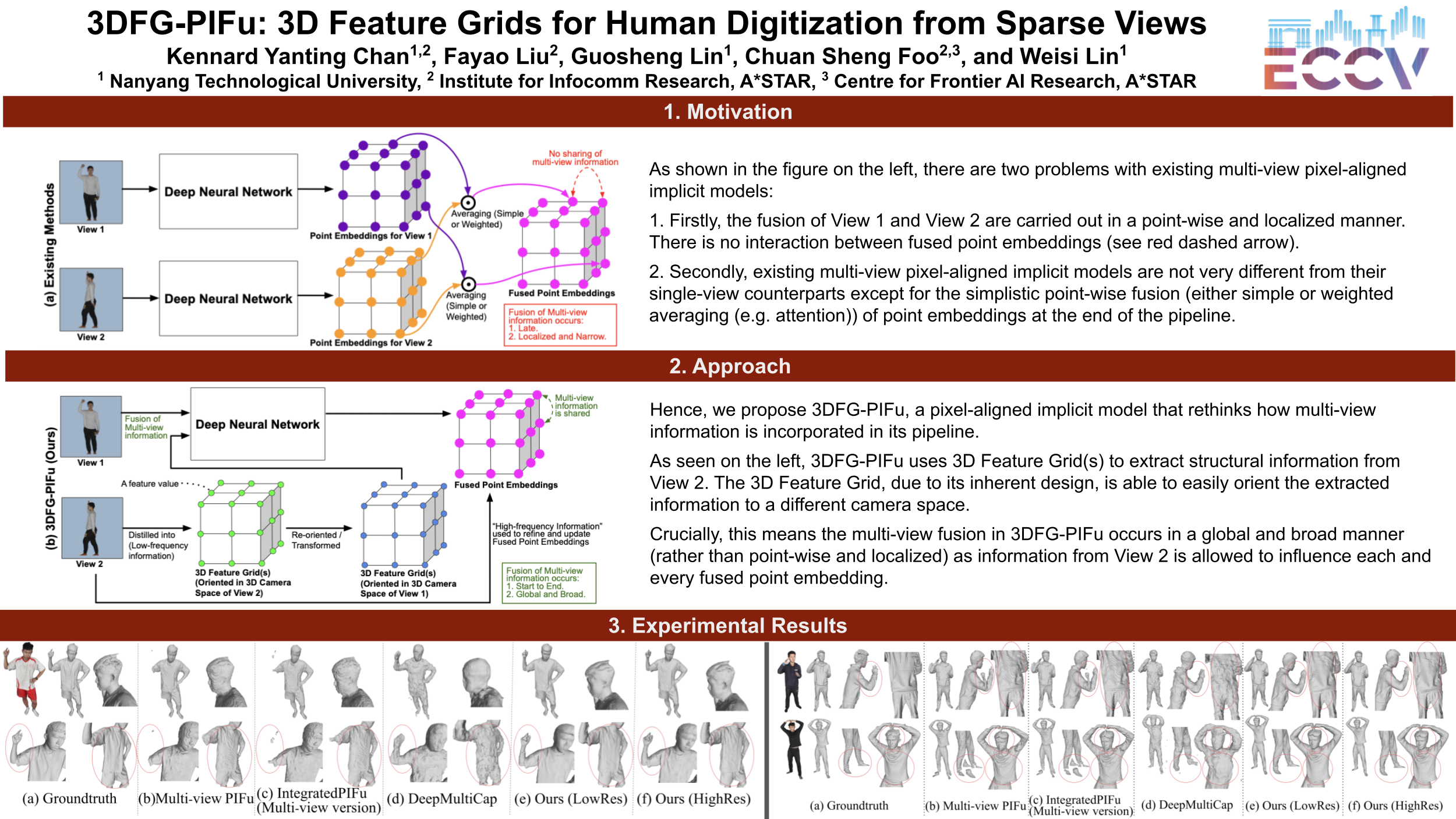
Pixel-aligned implicit models, such as Multi-view PIFu, DeepMultiCap, DoubleField, and SeSDF, are well-established methods for reconstructing a clothed human from sparse views. However, given V images, these models would only combine features from these images in a point-wise and localized manner. In other words, the V images are processed individually and are only combined in a very narrow fashion at the end of the pipeline. To a large extent, this defeats the purpose of having multi-view information since the multi-view task in question is predominantly treated as a single-view task. To resolve this, we introduce 3DFG-PIFu, a pixel-aligned implicit model that exploits multi-view information right from the start and all the way to the end of the pipeline. Our 3DFG-PIFu makes use of 3D Feature Grids to combine features from V images in a global manner (rather than point-wise or localized) and throughout the pipeline. Other than the 3D Feature Grids, 3DFG-PIFu also proposes an iterative mechanism that refines and updates an existing output human mesh using the different views. Moreover, 3DFG-PIFu introduces SDF-based SMPL-X features, which is a new method of incorporating a SMPL-X mesh into a pixel-aligned implicit model. Our experiments show that 3DFG-PIFu significantly outperforms SOTA models both qualitatively and quantitatively. Our code will be published.