ReMamber: Referring Image Segmentation with Mamba Twister
{kind=link}
Abstract
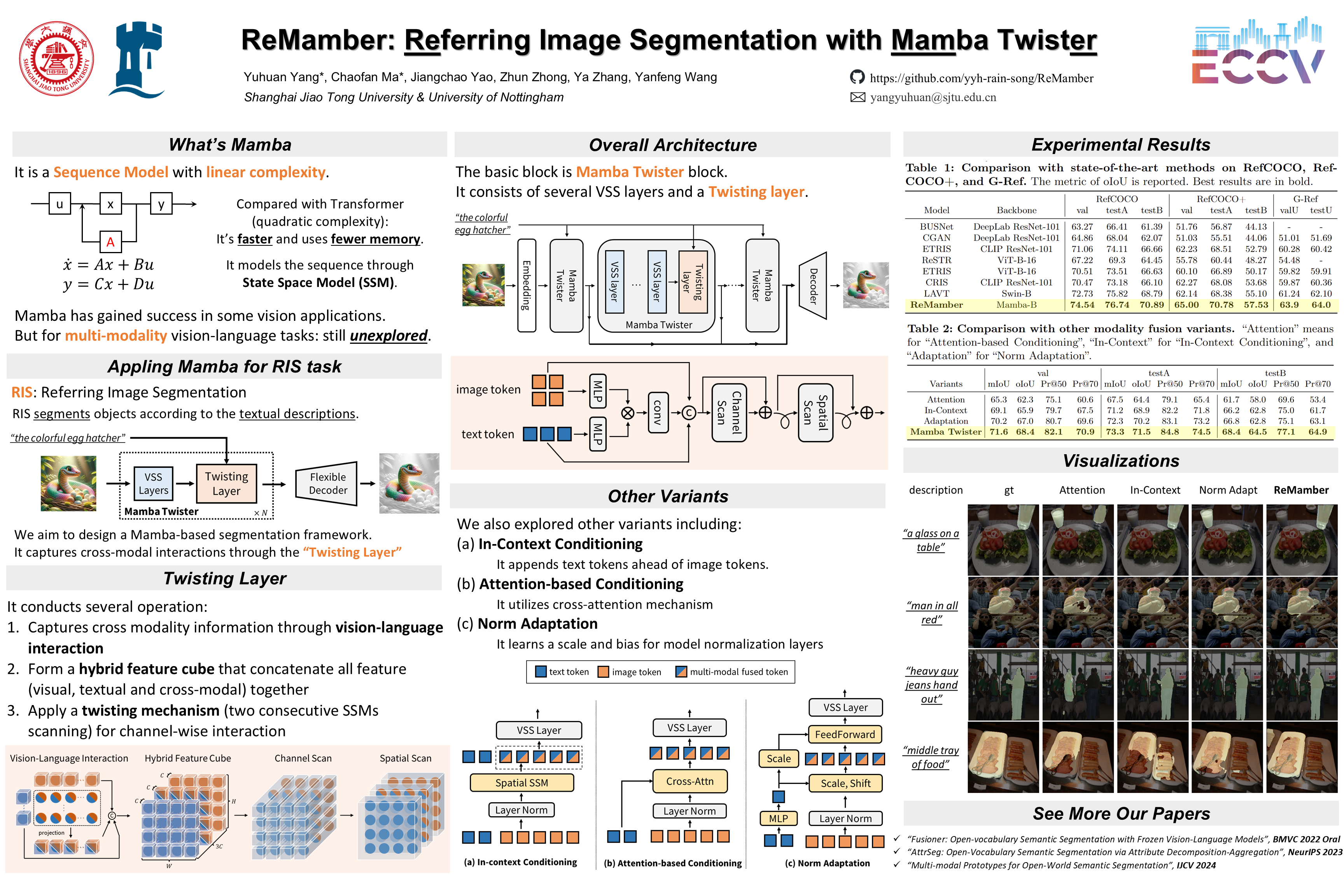
Referring Image Segmentation (RIS) leveraging transformers has achieved great success on the interpretation of complex visual-language tasks. However, the quadratic computation cost makes it difficult in capturing long-range visual-language dependencies, which is particularly important for the context of large-size images with long textual descriptions. Fortunately, Mamba addresses this with efficient linear complexity in processing. However, directly applying Mamba to multi-modal interactions presents challenges, primarily due to inadequate channel interactions for the effective fusion of multi-modal data. In this paper, we propose \methodname, a novel RIS architecture that integrates the efficiency of Mamba with a multi-modal Mamba Twister block. The Mamba Twister explicitly models image-text interaction, and fuses textual and visual features through its unique channel and spatial twisting mechanism. We achieve state-of-the-art on all three benchmarks. Moreover, we conduct thorough analyses of \methodname and discuss other fusion designs using Mamba. These provide valuable perspectives for future research. The code will be released upon publication.