Efficient and Versatile Robust Fine-Tuning of Zero-shot Models
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
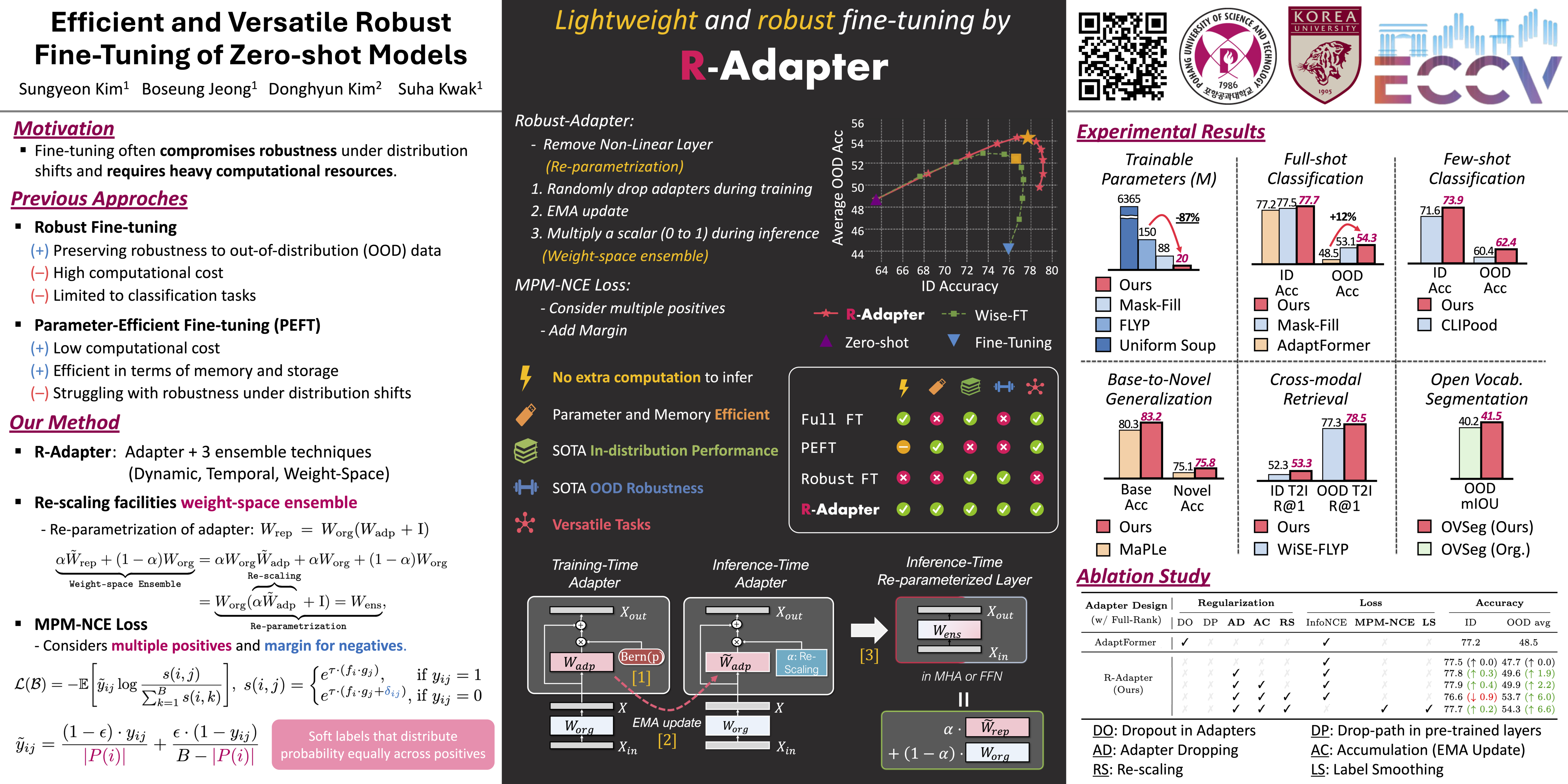
Large-scale image-text pre-trained models enable zero-shot classification and provide consistent accuracy across various data distributions. Nonetheless, optimizing these models in downstream tasks typically requires fine-tuning, which reduces generalization to out-of-distribution (OOD) data and demands extensive computational resources. We introduce Robust Adapter (R-Adapter), a novel method for fine-tuning zero-shot models to downstream tasks while simultaneously addressing both these issues. Our method integrates lightweight modules into the pre-trained model and employs novel self-ensemble techniques to boost OOD robustness and reduce storage expenses substantially. Furthermore, we propose MPM-NCE loss designed for fine-tuning on vision-language downstream tasks. It ensures precise alignment of multiple image-text pairs and discriminative feature learning. By extending the benchmark for robust fine-tuning beyond classification to include diverse tasks such as cross-modal retrieval and open vocabulary segmentation, we demonstrate the broad applicability of R-Adapter. Our extensive experiments demonstrate that R-Adapter achieves state-of-the-art performance across a diverse set of tasks, tuning only 13% of the parameters of the CLIP encoders.