Unsupervised Representation Learning by Balanced Self Attention Matching
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
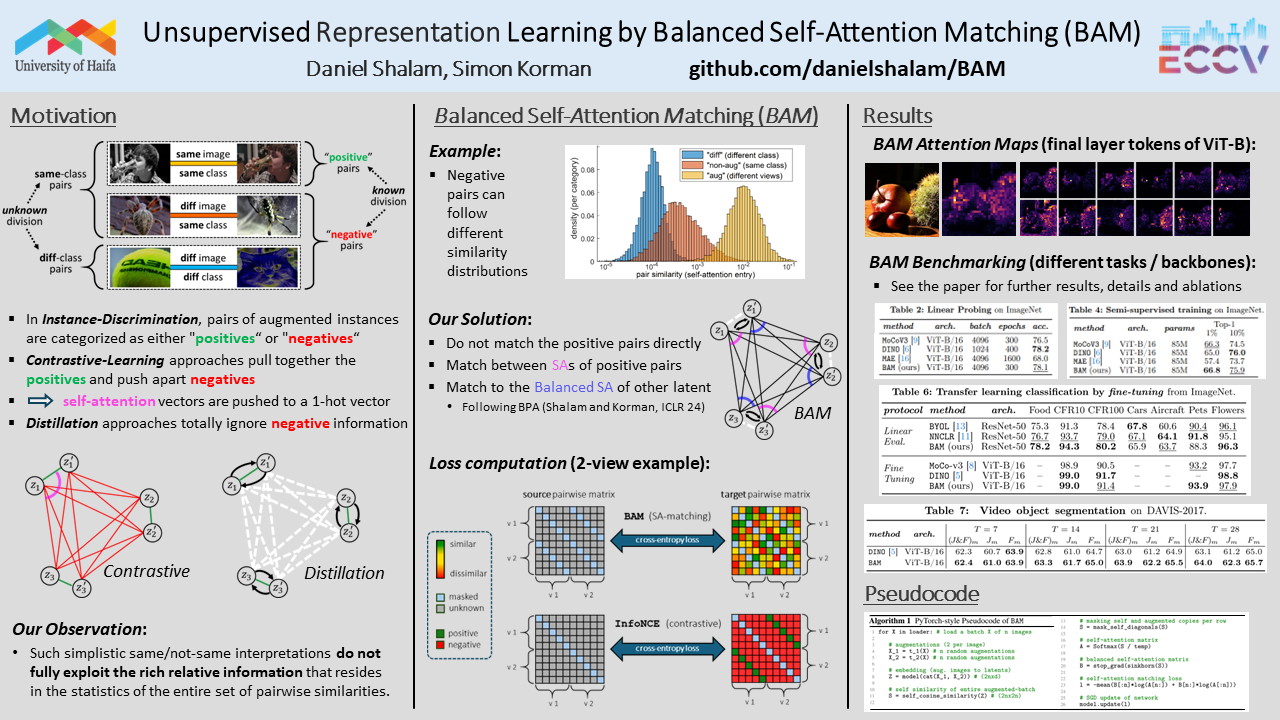
Many leading self-supervised methods for unsupervised representation learning, in particular those for embedding image features, are built on variants of the instance discrimination task, whose optimization is known to be prone to instabilities that can lead to feature collapse. Different techniques have been devised to circumvent this issue, including the use of negative pairs with different contrastive losses, the use of external memory banks, and breaking of symmetry by using separate encoding networks with possibly different structures. Our method, termed BAM, rather than directly matching features of different views (augmentations) of input images, is based on matching their self-attention vectors, which are the distributions of similarities to the entire set of augmented images of a batch. We obtain rich representations and avoid feature collapse by minimizing a loss that matches these distributions to their globally balanced and entropy regularized version, which is obtained through a simple self-optimal-transport computation. We ablate and verify our method through a wide set of experiments that show competitive performance with leading methods on both semi-supervised and transfer-learning benchmarks. Our implementation and pre-trained models will be made publicly available.