A Simple Baseline for Spoken Language to Sign Language Translation with 3D Avatars
{kind=link}
Abstract
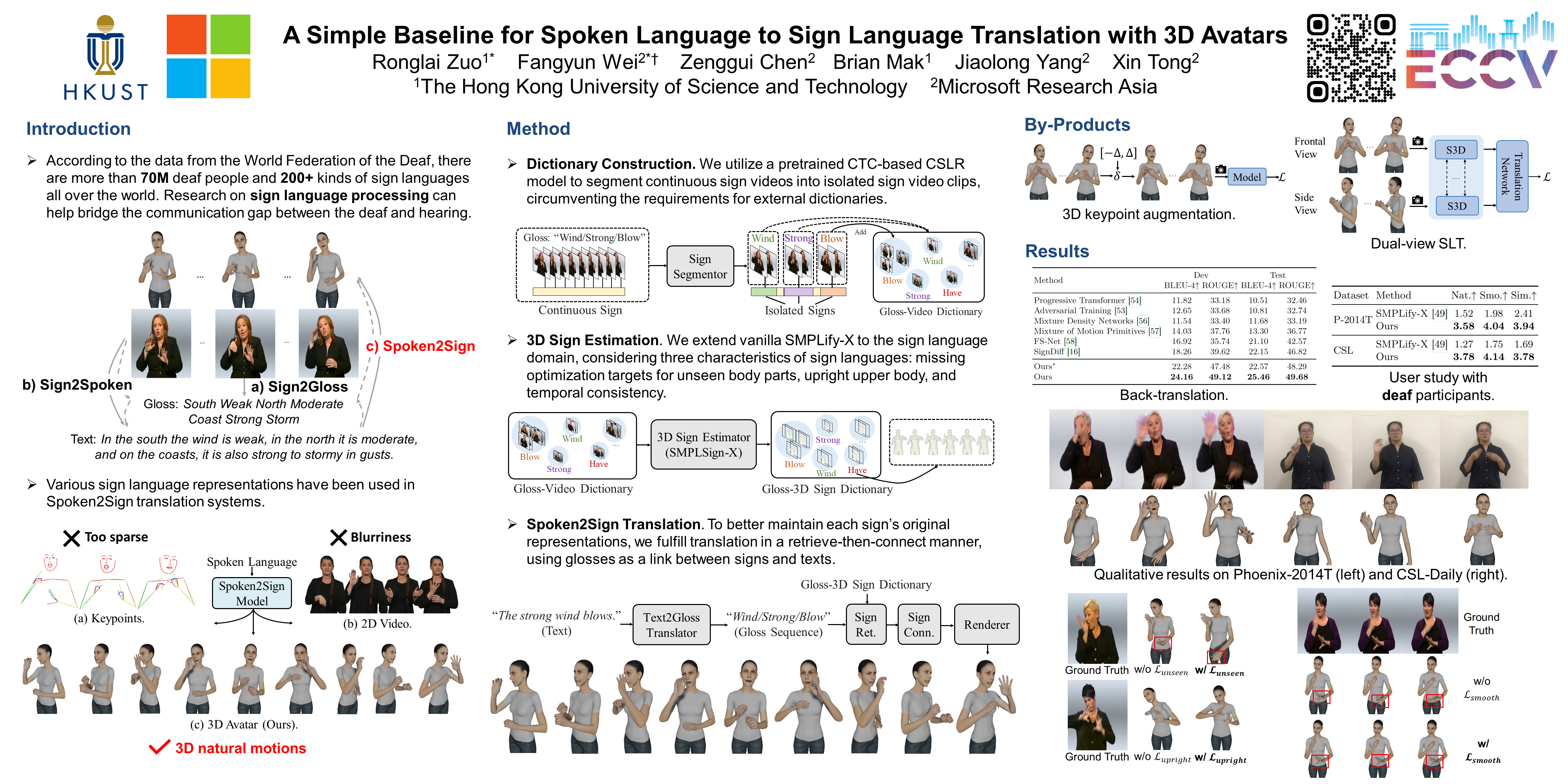
The objective of this paper is to develop a functional system for translating spoken languages into sign languages, referred to as Spoken2Sign translation. The Spoken2Sign task is orthogonal and complementary to traditional sign language to spoken language (Sign2Spoken) translation. To enable Spoken2Sign translation, we present a simple baseline consisting of three steps: 1) creating a gloss-video dictionary using existing Sign2Spoken benchmarks; 2) estimating a 3D sign for each sign video in the dictionary; 3) training a Spoken2Sign model, which is composed of a Text2Gloss translator, a sign connector, and a rendering module, with the aid of the yielded gloss-3D sign dictionary. The translation results are then displayed through a sign avatar. As far as we know, we are the first to present the Spoken2Sign task in an output format of 3D signs. In addition to its capability of Spoken2Sign translation, we also demonstrate that two by-products of our approach—3D keypoint augmentation and multi-view understanding—can assist in keypoint-based sign language understanding. Code and models will be released to facilitate future research.