Multi-modal Relation Distillation for Unified 3D Representation Learning
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
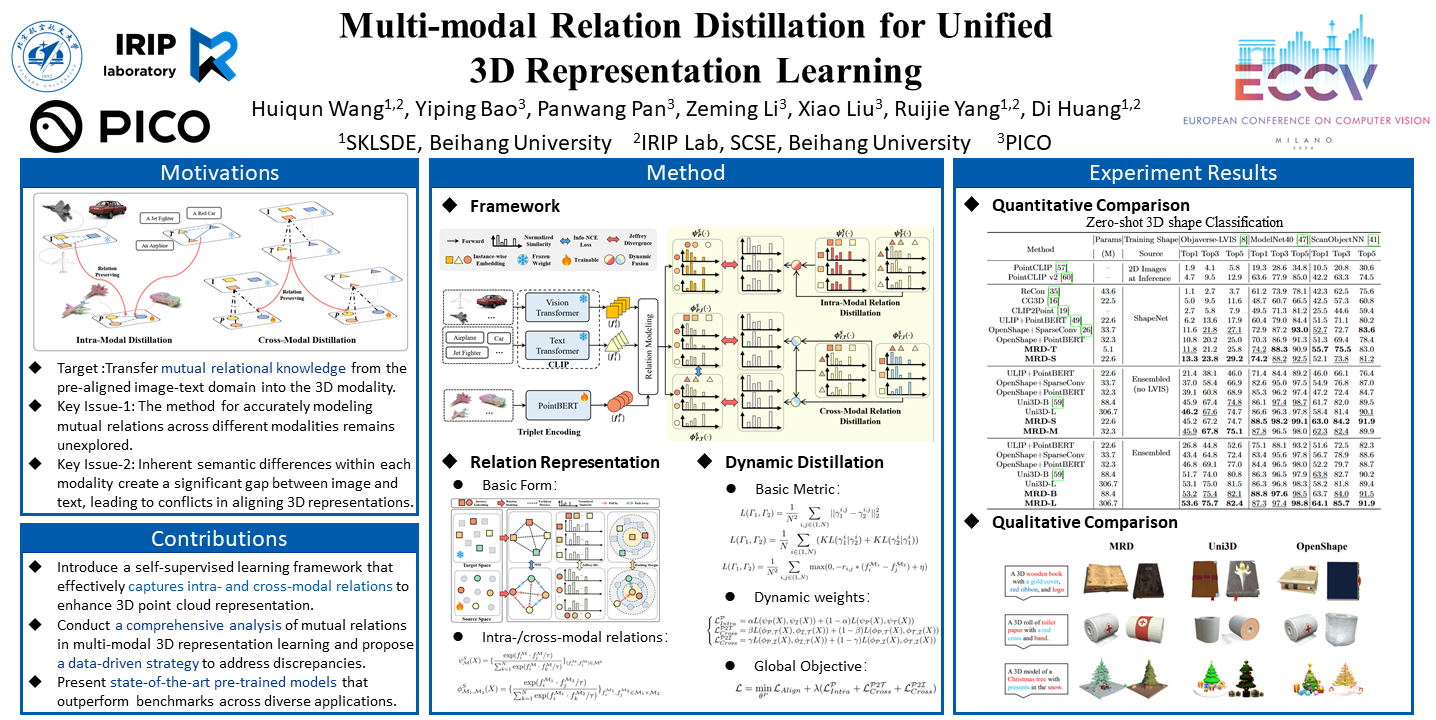
Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning multi-modal features across 3D shapes, corresponding 2D images, and language descriptions. However, this straightforward alignment often overlooks the intricate structural relationships among the samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pretraining framework designed to effectively distill state-of-the-art large multi-modal models into 3D backbones. MRD focuses on distilling both the intra-relations within each modality and the cross-relations between different modalities, aiming to produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering state-of-the-art performance.