T-MAE: Temporal Masked Autoencoders for Point Cloud Representation Learning
{kind=link}
Abstract
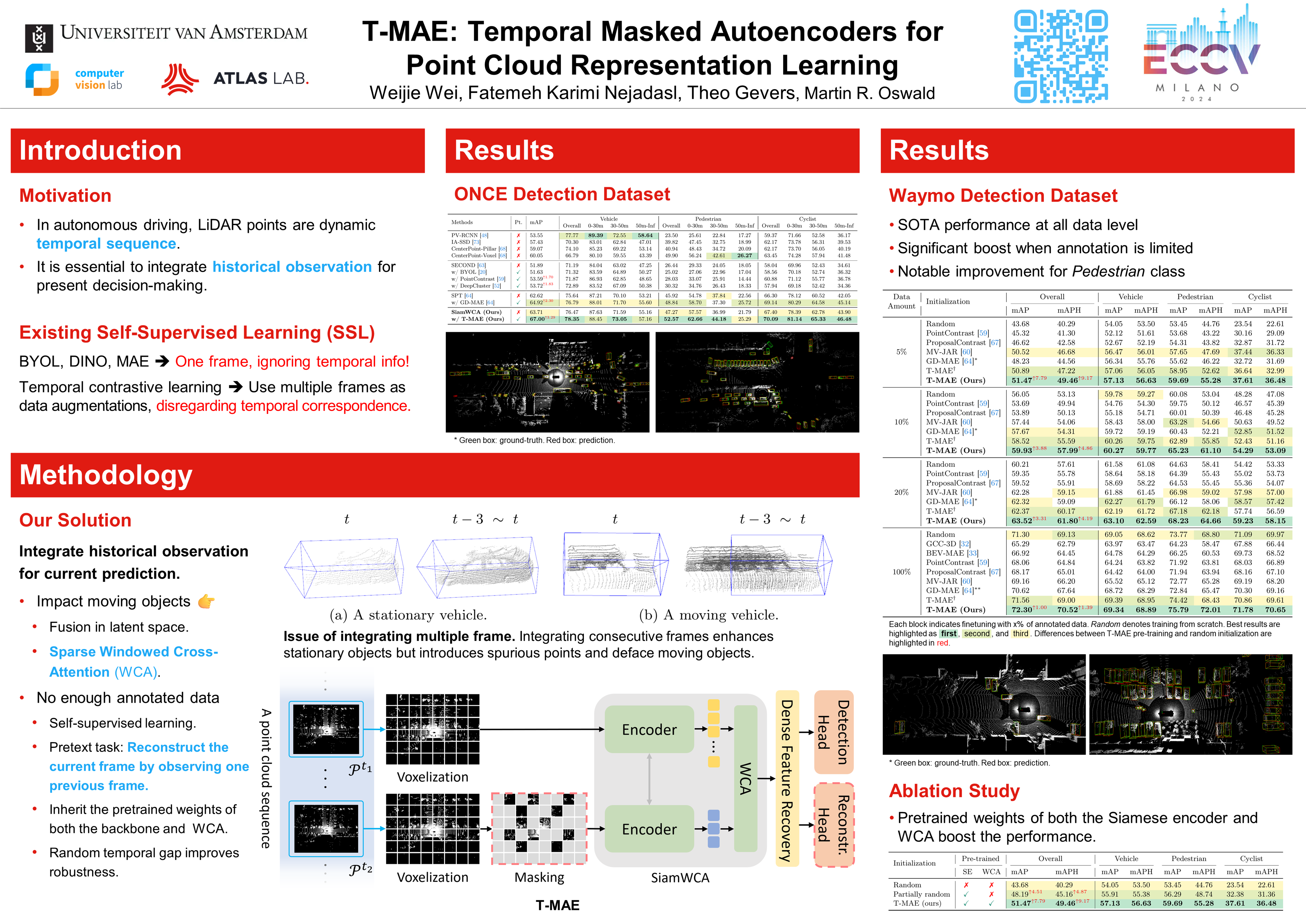
The scarcity of annotated data in LiDAR point cloud understanding hinders effective representation learning. Consequently, scholars have been actively investigating efficacious self-supervised pre-training paradigms. Nevertheless, temporal information, which is inherent in the LiDAR point cloud sequence, is consistently disregarded. To better utilize this property, we propose an effective pre-training strategy, namely Temporal Masked Auto-Encoders (T-MAE), which takes as input temporally adjacent frames and learns temporal dependency. A SiamWCA backbone, containing a Siamese encoder and a windowed cross-attention (WCA) module, is established for the two-frame input. Considering that the movement of an ego-vehicle alters the view of the same instance, temporal modeling also serves as a robust and natural data augmentation, enhancing the comprehension of target objects. SiamWCA is a powerful architecture but heavily relies on annotated data. Our T-MAE pre-training strategy alleviates its demand on annotated data. Comprehensive experiments demonstrate that T-MAE achieves the best performance on both Waymo and ONCE datasets among competitive self-supervised approaches.