CarFormer: Self-Driving with Learned Object-Centric Representations
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
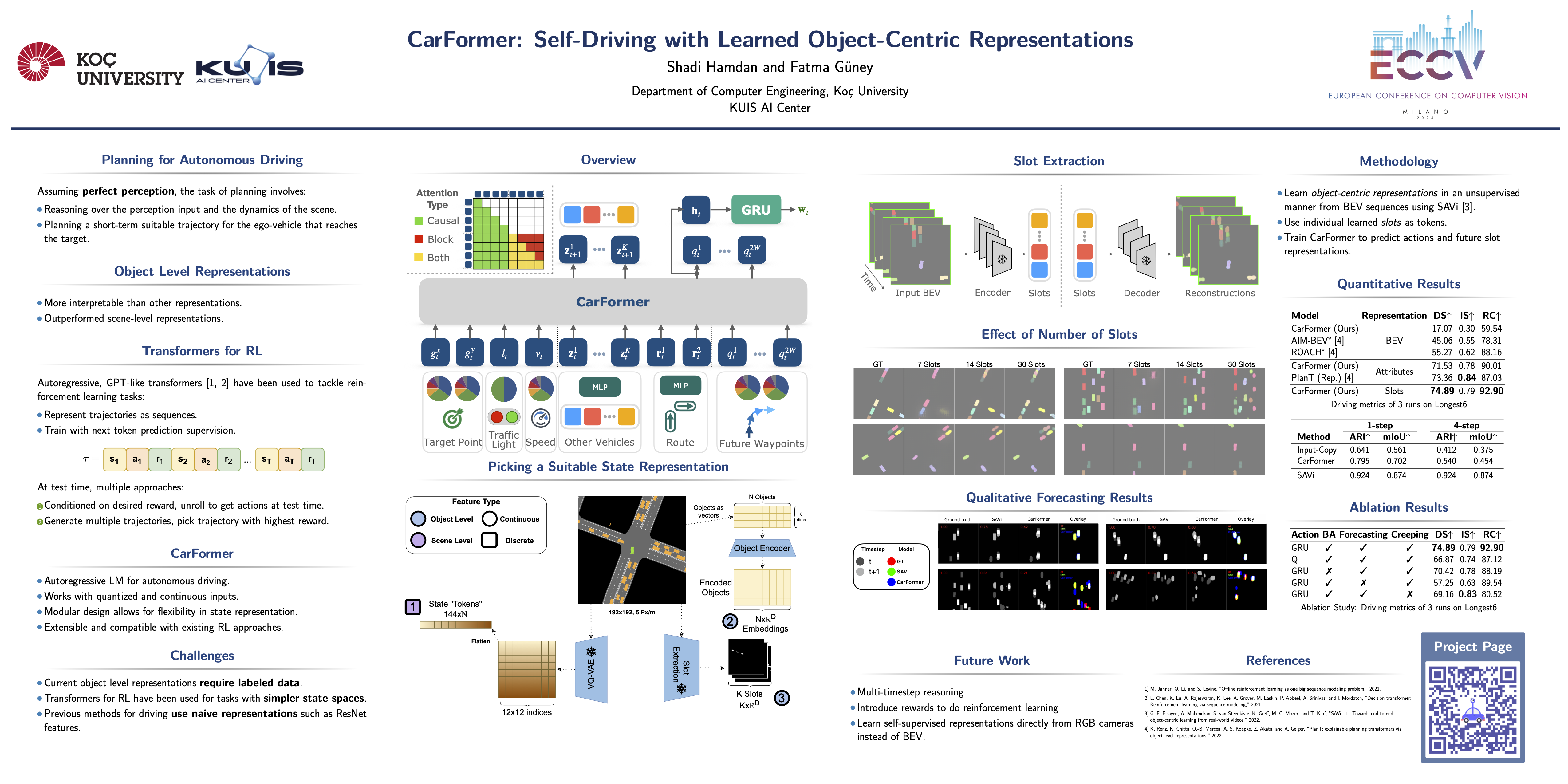
The choice of representation plays a key role in self-driving. Bird’s eye view (BEV) representations have shown remarkable performance in recent years. In this paper, we propose to learn object-centric representations in BEV to distill a complex scene into more actionable information for self-driving. We first learn to place objects into slots with a slot attention model on BEV sequences. Based on these object-centric representations, we then train a transformer to learn to drive as well as reason about the future of other vehicles. We found that object-centric slot representations outperform both scene-level and object-level approaches that use the exact attributes of objects. Slot representations naturally incorporate information about objects from their spatial and temporal context such as position, heading, and speed without explicitly providing it. Our model with slots achieves increased coverage of the provided routes and, consequently, a higher driving score, with a lower variance across multiple runs, affirming slots as a reliable alternative in object-centric approaches. Additionally, we validate our model’s performance as a world model through forecasting experiments, demonstrating its capability to accurately predict future slot representations.