Visual Relationship Transformation
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
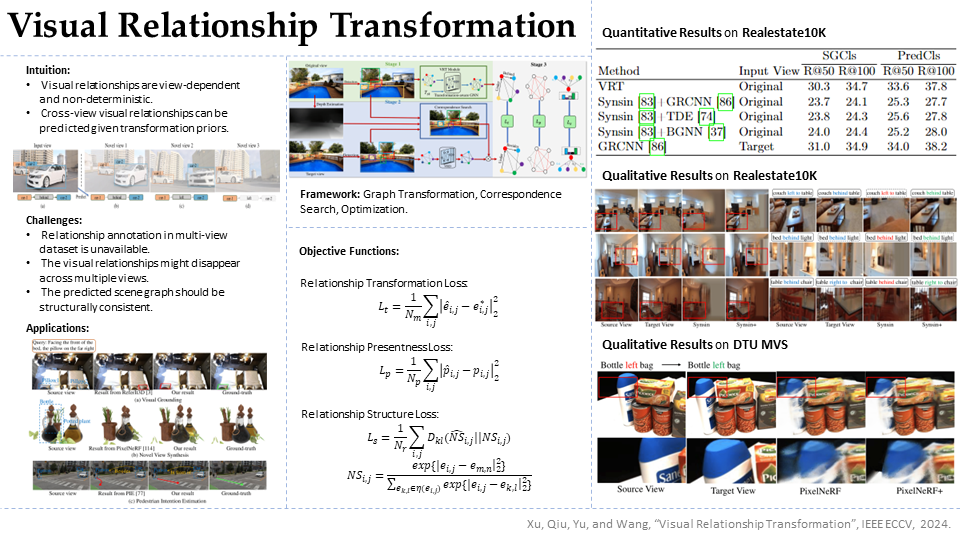
What will be the relationships between objects in a novel view? We strive to answer this question by investigating a new visual cognition task, termed visual relationship transformation or VRT. Unlike prior visual relationship detection task that works on visible view images, VRT aims to predict the relationships in unseen novel views from a single observed source view. Towards solving VRT, we propose an end-to-end deep approach that, given an observed view image and inter-view transformations, learns to predict the relationships in novel views. Specifically, we introduce an equivariant graph neural network to predict the relationships between objects in novel views, which is achieved by enforcing the transformation equivariance of the learned relationship representations. Simultaneously, a relationship presentness mask is learned for pruning the invisible ones, thus enabling the visible relationship prediction in novel views. To this end, VRT provides supplementary cues for accomplishing novel-view-related tasks, such as visual grounding (VG), novel view synthesis (NVS), and pedestrian intention estimation (PIE). In the experiments, adopting VRT as a plug-in module results in considerable performance improvements in VG, NVS, and PIE across all datasets.