Self-Supervised Audio-Visual Soundscape Stylization
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
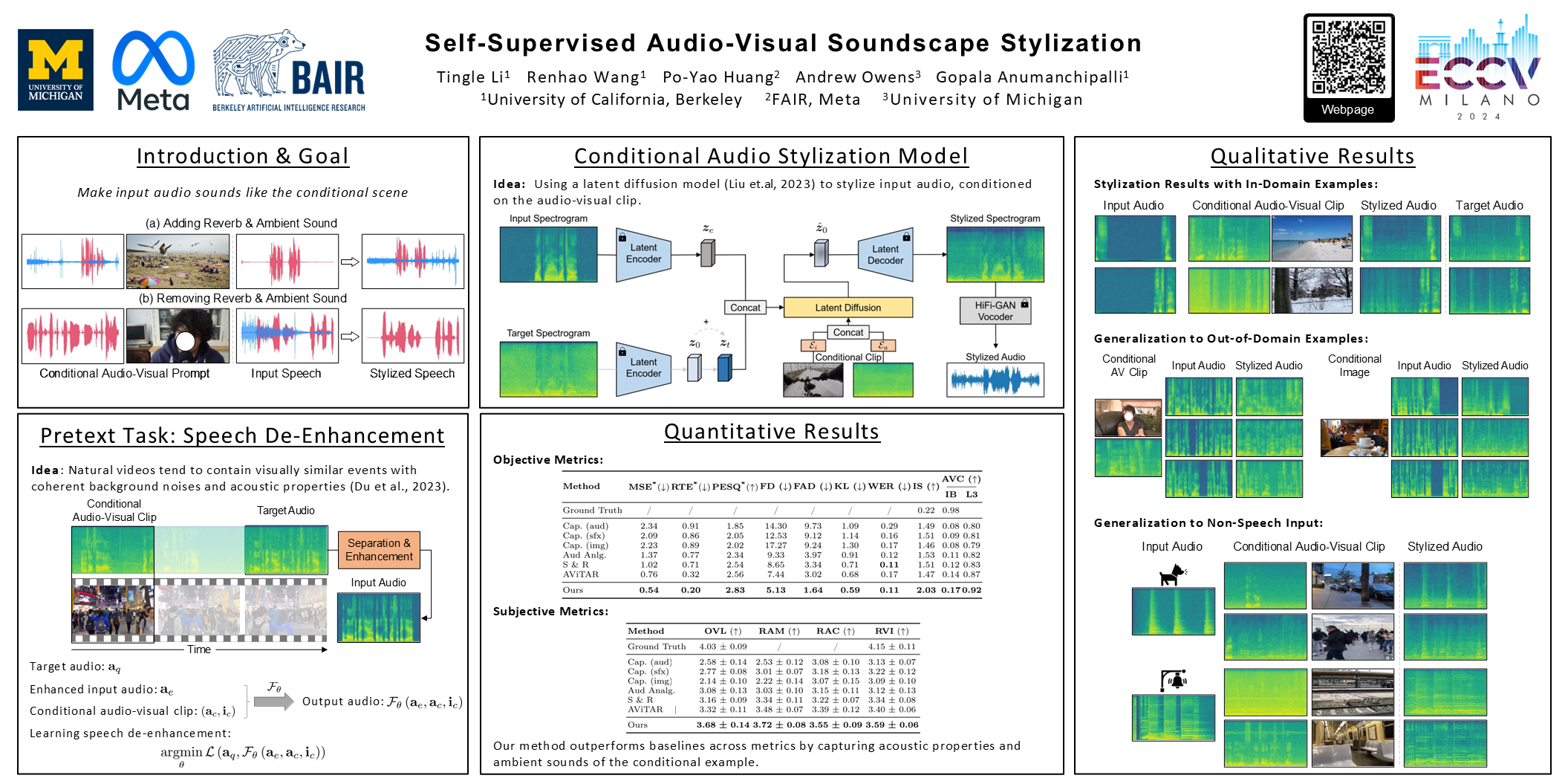
Speech sounds convey a great deal of information about the scenes, resulting in a variety of effects ranging from reverberation to additional ambient sounds. In this paper, we manipulate input speech to sound as though it was recorded within a different scene, given an audio-visual conditional example recorded from that scene. Our model learns through self-supervision, taking advantage of the fact that natural video contains recurring sound events and textures. We extract an audio clip from a video and apply speech enhancement. We then train a latent diffusion model to recover the original speech, using another audio-visual clip taken from elsewhere in the video as a conditional hint. Through this process, the model learns to transfer the conditional example's sound properties to the input speech. We show that our model can be successfully trained using unlabeled, in-the-wild videos, and that an additional visual signal can improve its sound prediction abilities.