An Explainable Vision Question Answer Model via Diffusion Chain-of-Thought
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
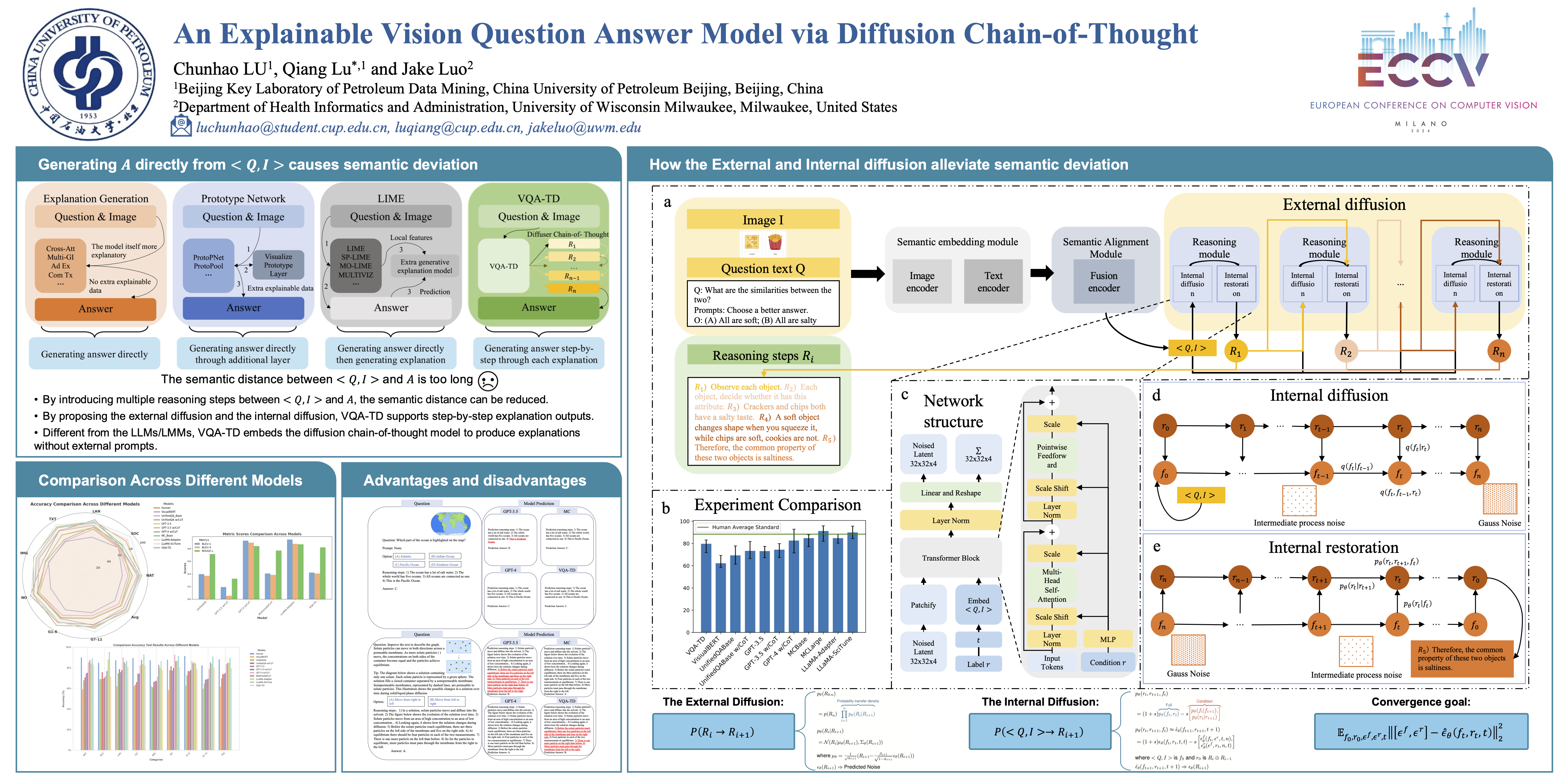
Explainable visual question-answering research focuses on generating explanations for answers. However, in complex VQA scenarios, there can be a significant semantic distance between the question and the answer. This means that generating explanations solely for the answer can lead to a semantic discrepancy between the content of the explanation and the question-answering content. To address this, we propose a step-by-step reasoning approach to reduce such semantic discrepancies. Additionally, the task of explaining VQA should include generating explanations for the reasoning steps to obtain explanations for the final answer. We introduce a diffusion chain-of-thought model to implement this step-by-step reasoning and the explanation process. The model consists of two processes: the external diffusion and the internal diffusion. The external diffusion process generates explanations for each reasoning step, while the internal diffusion process describes the probability of the question transitioning to each step of the explanation. Through experiments on eight sub-tasks in the ScienceQA dataset, we demonstrate that our diffusion chain-of-thought model outperforms GPT-3.5 in terms of the answer accuracy and the explanation ability while only using 1% of GPT-3.5's parameters. Furthermore, the model approaches GPT-4, Llama, and so on in eight sub-tasks.