Parameter-Efficient and Memory-Efficient Tuning for Vision Transformer: A Disentangled Approach
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
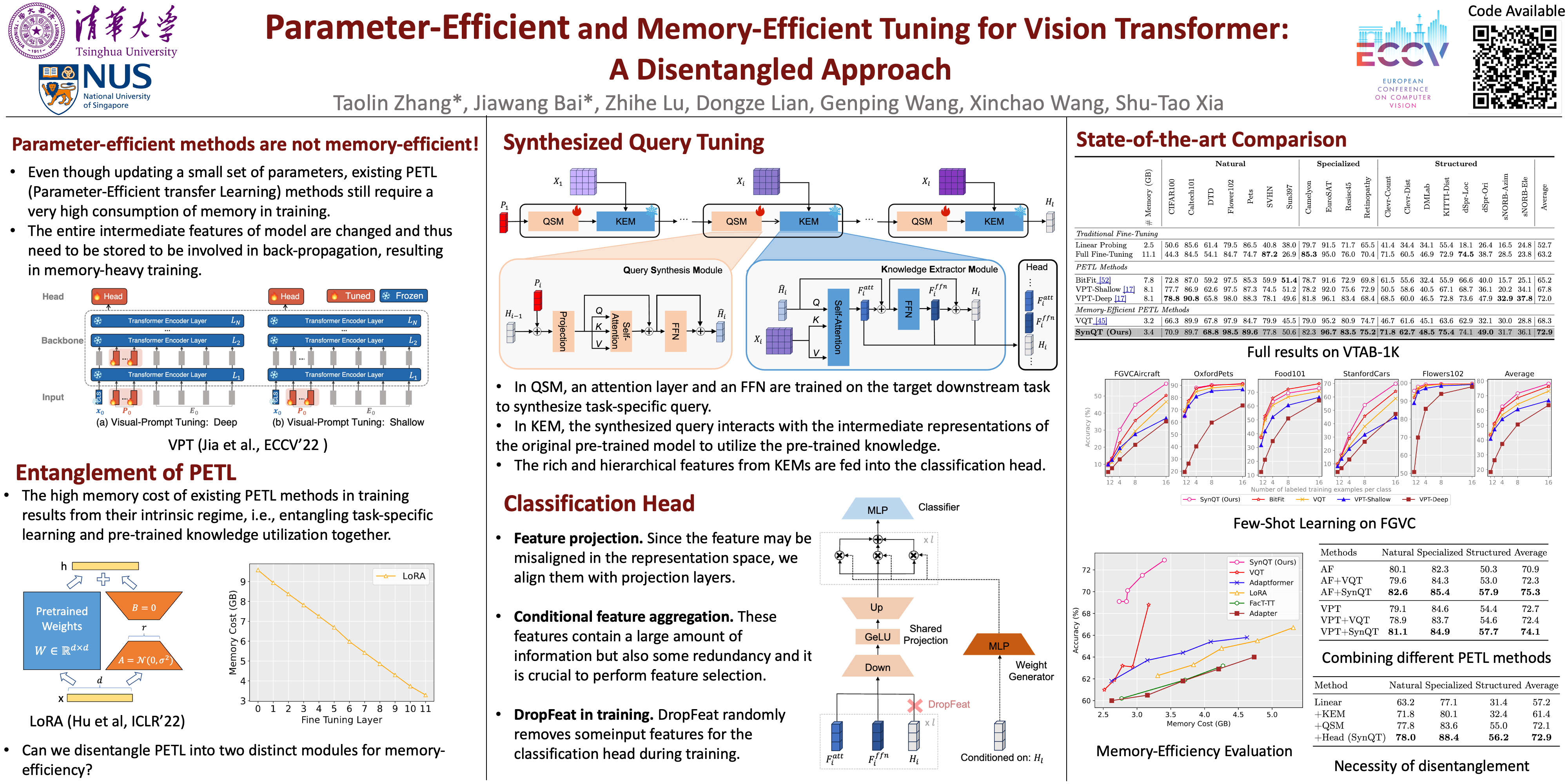
Recent works on parameter-efficient transfer learning (PETL) show the potential to adapt a pre-trained Vision Transformer to downstream recognition tasks with only a few learnable parameters. However, since they usually insert new structures into the pre-trained model, entire intermediate features of that model are changed and thus need to be stored to be involved in back-propagation, resulting in memory-heavy training. We solve this problem from a novel disentangled perspective, i.e., dividing PETL into two aspects: task-specific learning and pre-trained knowledge utilization. Specifically, we synthesize the task-specific query with a learnable and lightweight module, which is independent of the pre-trained model. The synthesized query equipped with task-specific knowledge serves to extract the useful features for downstream tasks from the intermediate representations of the pre-trained model in a query-only manner. Built upon these features, a customized classification head is proposed to make the prediction for the input sample. Given that our method employs a extremely lightweight architecture and avoids the use of heavy intermediate features for running gradient descent, it demonstrates limited memory usage in training. Notably, extensive experiments manifest that our method achieves state-of-the-art performance under memory constraints, showcasing its applicability in real-world situations.