Vision-Language Action Knowledge Learning for Semantic-Aware Action Quality Assessment
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
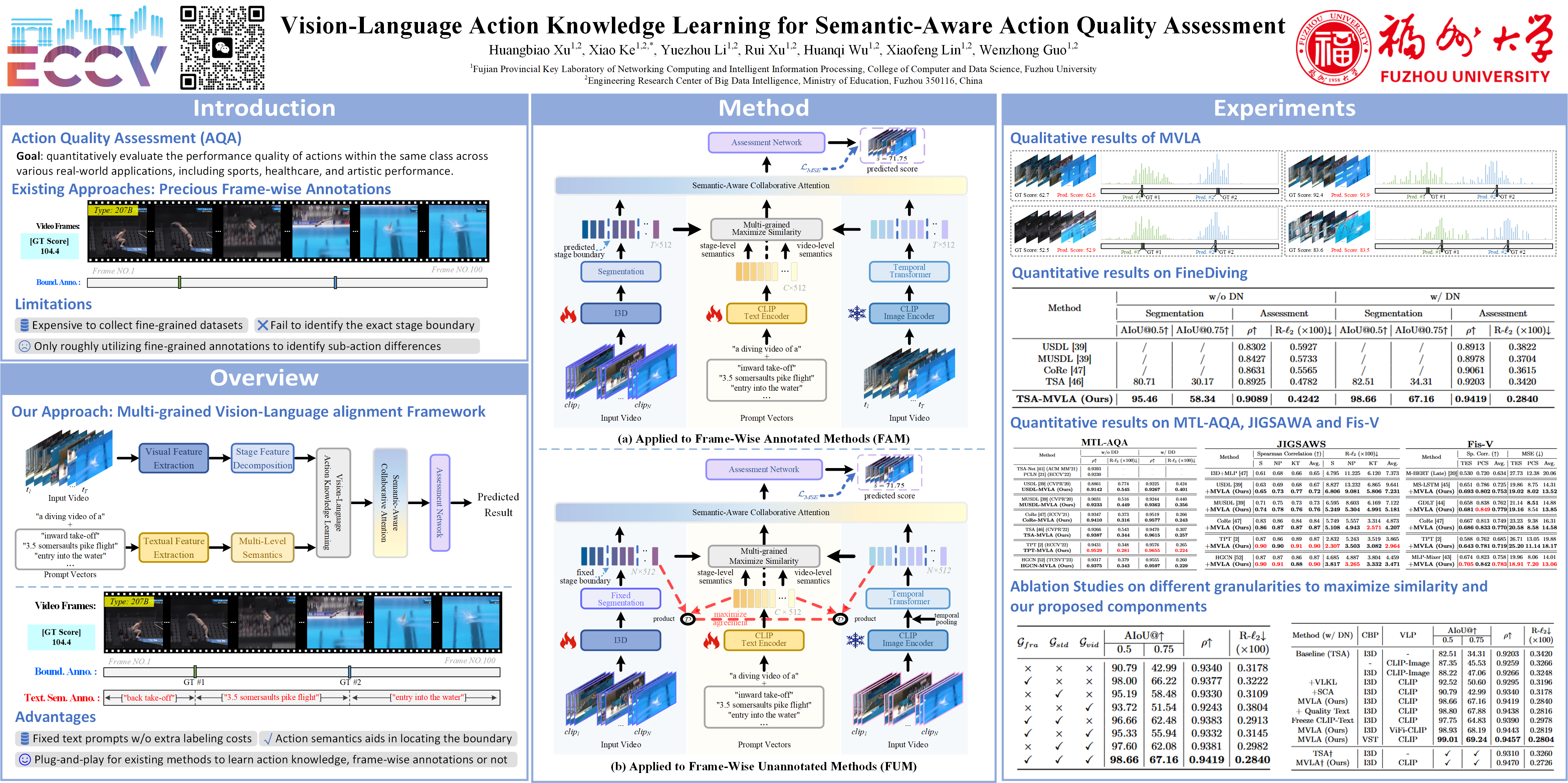
Action quality assessment (AQA) is a challenging vision task that requires discerning and quantifying subtle differences in actions from the same class. While recent research has made strides in creating fine-grained annotations for more precise analysis, existing methods primarily focus on coarse action segmentation, leading to limited identification of discriminative action frames. To address this issue, we propose a Vision-Language Action Knowledge Learning approach for action quality assessment, along with a multi-grained alignment framework to understand different levels of action knowledge. In our framework, prior knowledge, such as specialized terminology, is embedded into video-level, stage-level, and frame-level representations via CLIP. We further propose a new semantic-aware collaborative attention module to prevent confusing interactions and preserve textual knowledge in cross-modal and cross-semantic spaces. Specifically, we leverage the powerful cross-modal knowledge of CLIP to embed textual semantics into image features, which then guide action spatial-temporal representations. Our approach can be plug-and-played with existing AQA methods, frame-wise annotations or not. Extensive experiments and ablation studies show that our approach achieves state-of-the-art on four public short and long-term AQA benchmarks: FineDiving, MTL-AQA, JIGSAWS, and Fis-V.