Semantic Residual Prompts for Continual Learning
{kind=link}
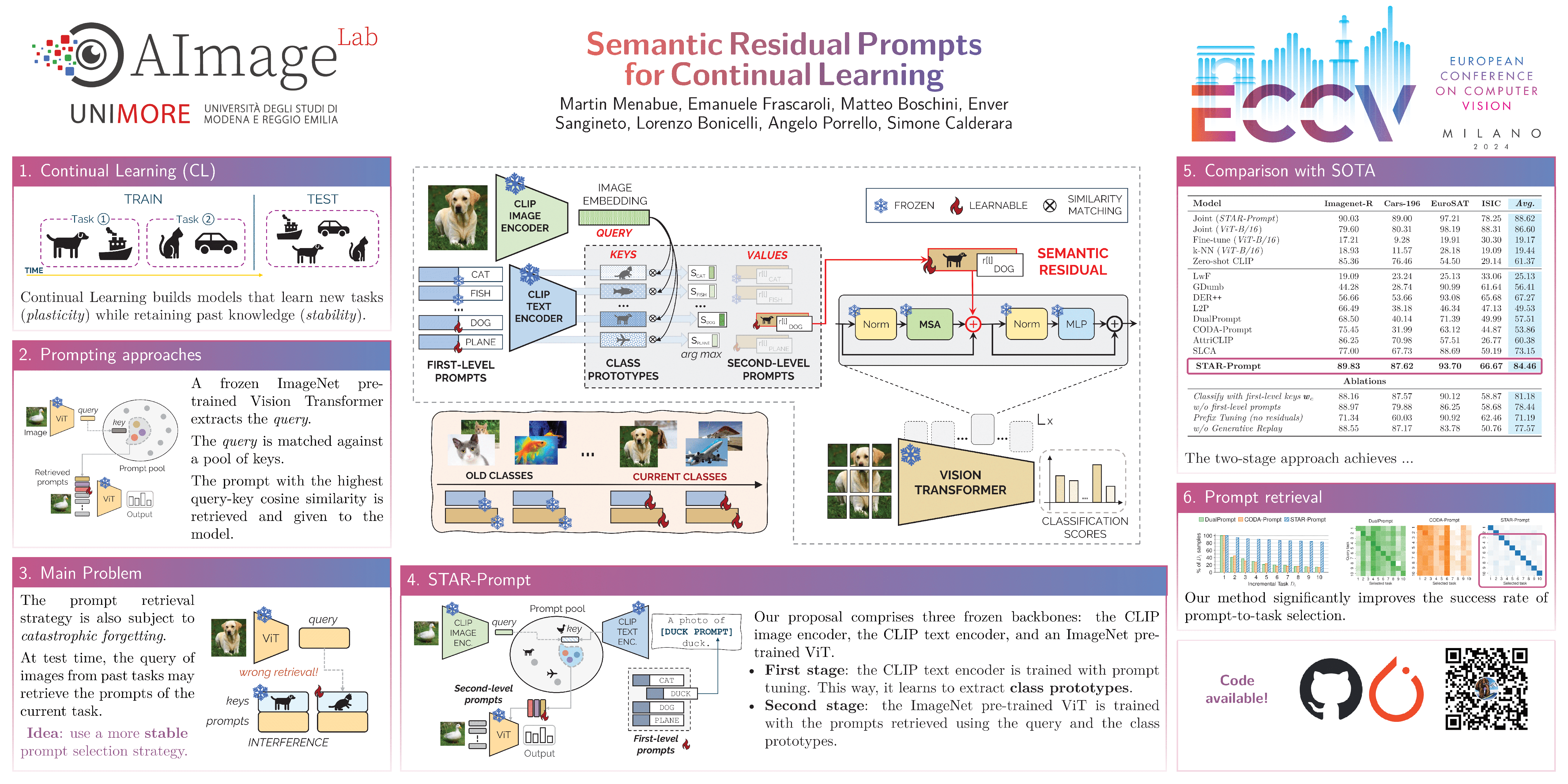
Abstract
Prompt-tuning methods for Continual Learning (CL) freeze a large pre-trained model and focus training on a few parameter vectors termed prompts. Most of these methods organize these vectors in a pool of key-value pairs, and use the input image as query to retrieve the prompts (values). However, as keys are learned while tasks progress, the prompting selection strategy is itself subject to catastrophic forgetting, an issue often overlooked by existing approaches. For instance, prompts introduced to accommodate new tasks might end up interfering with previously learned prompts. To make the selection strategy more stable, we ask a foundational model (CLIP) to select our prompt within a two-level adaptation mechanism. Specifically, the first level leverages standard textual prompts for the CLIP textual encoder, leading to stable class prototypes. The second level, instead, uses these prototypes along with the query image as keys to index a second pool. The retrieved prompts serve to adapt a pre-trained ViT, granting plasticity. In doing so, we also propose a novel residual mechanism to transfer CLIP semantics to the ViT layers. Through extensive analysis on established CL benchmarks, we show that our method significantly outperforms both state-of-the-art CL approaches and the zero-shot CLIP test. Notably, our findings hold true even for datasets with a substantial domain gap w.r.t. the pre-training knowledge of the backbone model, as showcased by experiments on satellite imagery and medical datasets. The codebase is available in the suppl. materials.