Good Teachers Explain: Explanation-Enhanced Knowledge Distillation
{kind=link}
Abstract
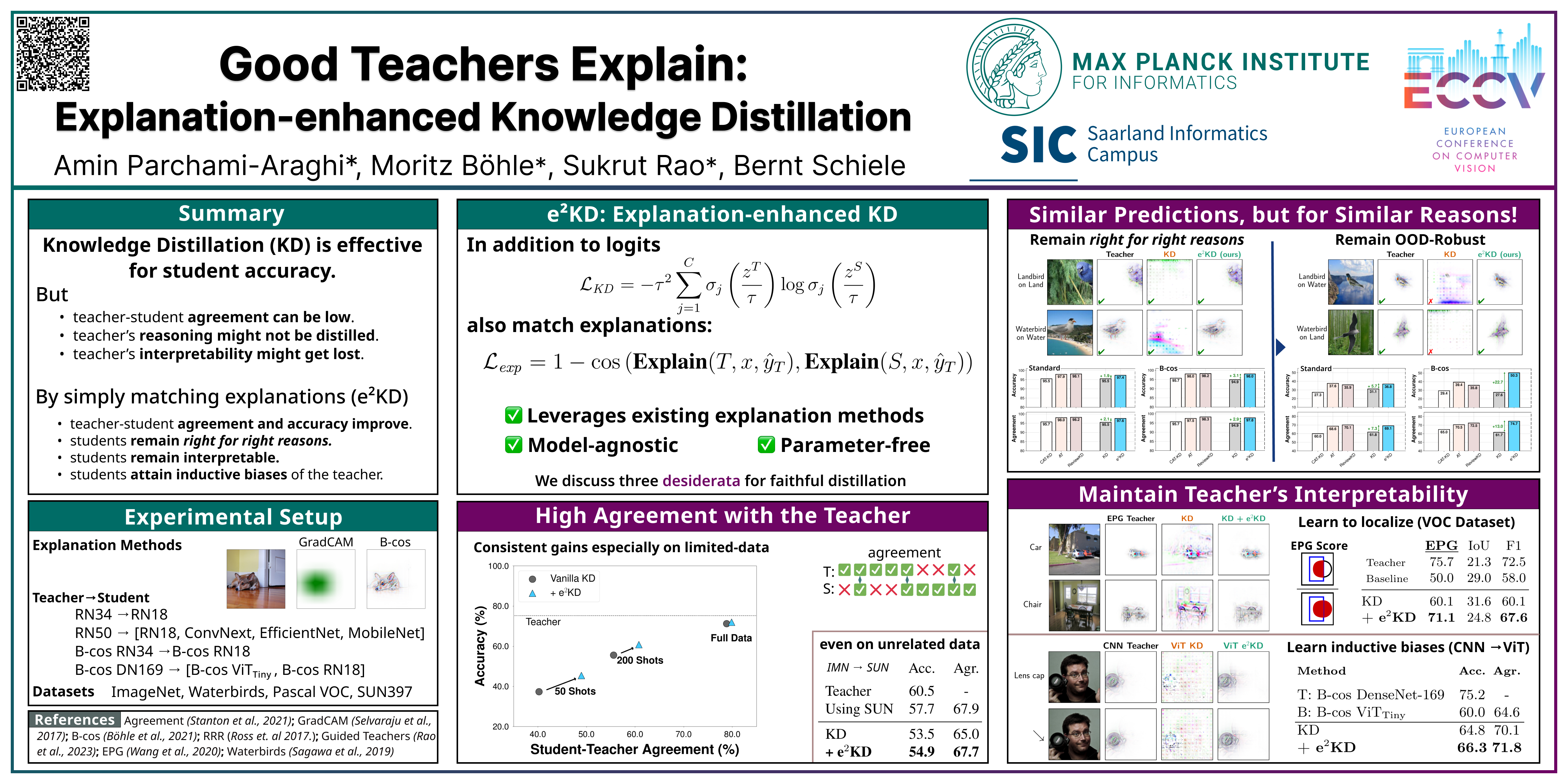
Knowledge Distillation (KD) has proven effective for compressing large teacher models into smaller student models. While it is well known that student models can achieve similar accuracies as the teachers, it has also been shown that they nonetheless often do not learn the same function. It is, however, often highly desirable that the student’s and teacher’s functions share similar properties such as basing the prediction on the same input features, as this ensures that students learn the ‘right features’ from the teachers. In this work, we explore whether this can be achieved by not only optimizing the classic KD loss but also the similarity of the explanations generated by the teacher and the student. Despite the idea being simple and intuitive, we find that our proposed ‘explanation-enhanced’ KD (e2KD) (1) consistently provides large gains in terms of accuracy and student-teacher agreement, (2) ensures that the student learns from the teacher to be right for the right reasons and to give similar explanations, and (3) is robust with respect to the model architectures, the amount of training data, and even works with ‘approximate’, pre-computed explanations.