Prompting Future Driven Diffusion Model for Hand Motion Prediction
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
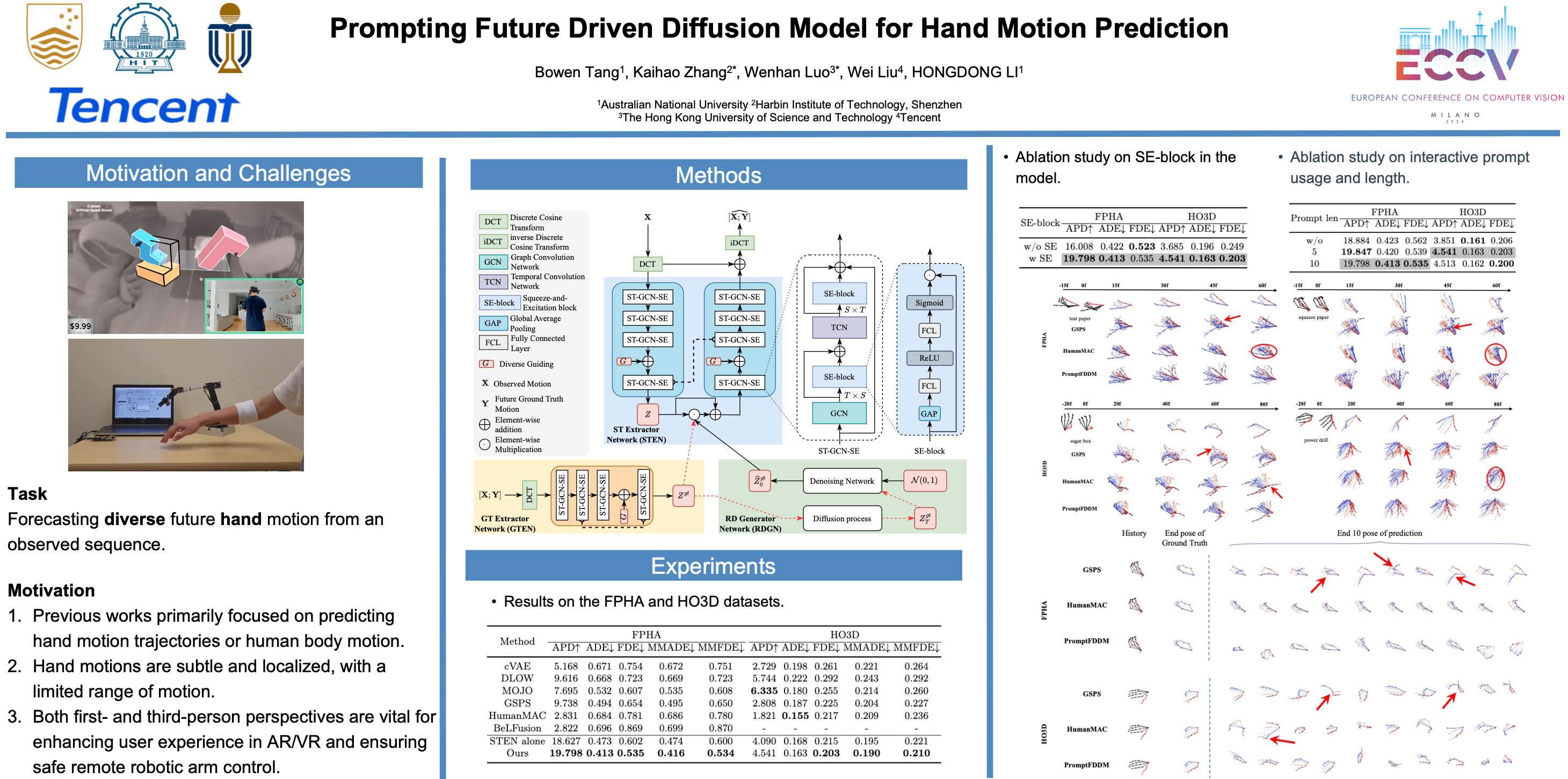
Hand motion prediction from both first- and third-person perspectives is vital for enhancing user experience in AR/VR and ensuring safe remote robotic arm control. Previous works typically focus on predicting hand motion trajectories or human body motion, with direct hand motion prediction remaining largely unexplored - despite the additional challenges posed by compact skeleton size. To address this, we propose a prompt-based Future Driven Diffusion Model (PromptFDDM) for predicting hand motion with guidance and prompts. Specifically, we develop a Spatial-Temporal Extractor Network (STEN) to predict hand motion with guidance, a Ground Truth Extractor Network (GTEN), and a Reference Data Generator Network (RDGN), which extract ground truth and substitute future data with generated reference data, respectively, to guide STEN. Additionally, interactive prompts generated from observed motions further enhance model performance. Experimental results on the FPHA and HO3D datasets demonstrate that the proposed PromptFDDM achieves state-of-the-art performance in both first- and third-person perspectives.