Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
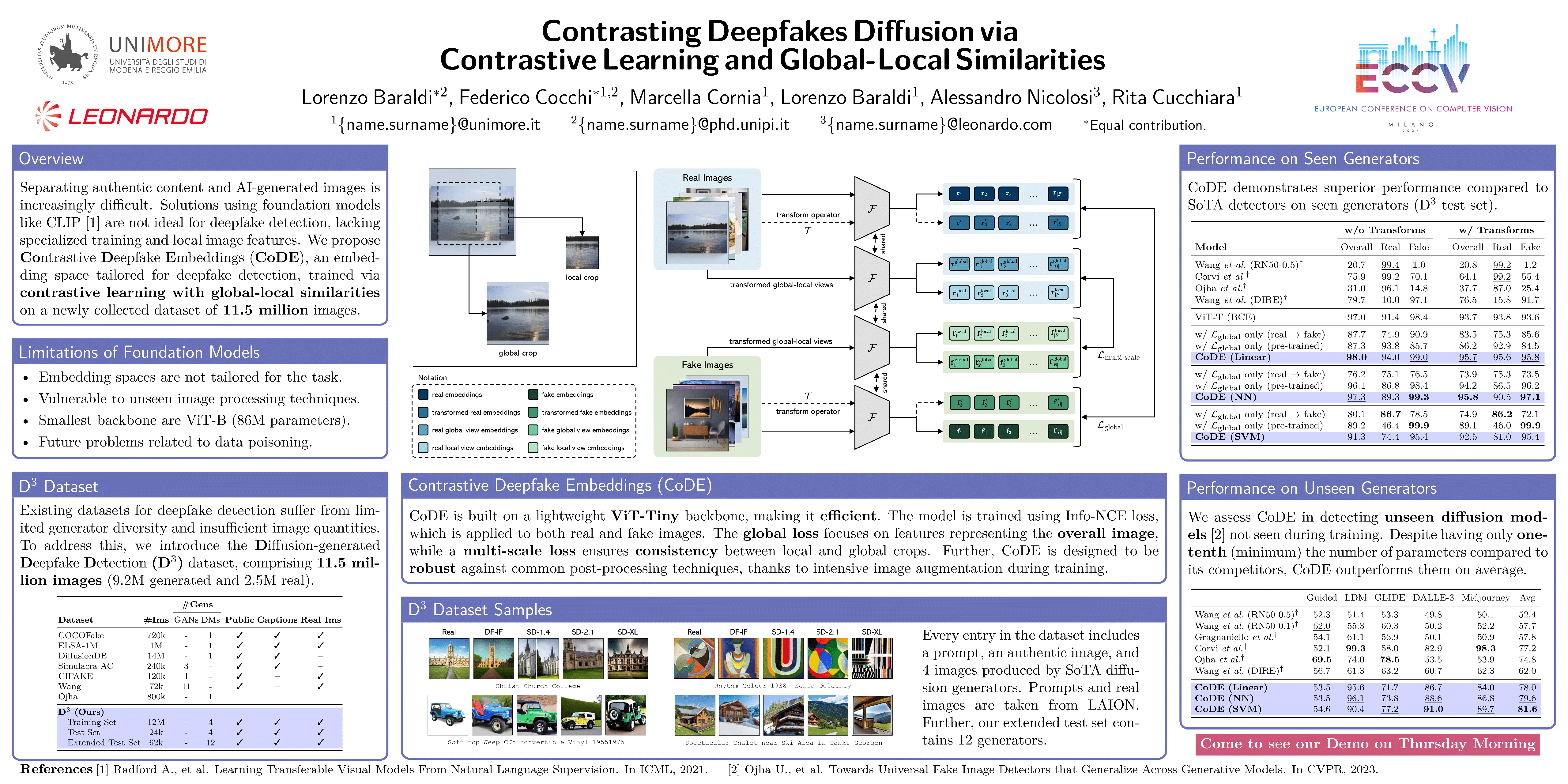
Discerning between authentic content and that generated by advanced AI methods has become increasingly challenging. While previous research primarily addresses the detection of fake faces, the identification of generated natural images has only recently surfaced. This prompted the recent exploration of solutions that employ foundation vision-and-language models, like CLIP. However, the CLIP embedding space is optimized for global image-to-text alignment and is not inherently designed for deepfake detection, neglecting the potential benefits of tailored training and local image features. In this study, we propose CoDE (Contrastive Deepfake Embeddings), a novel embedding space specifically designed for deepfake detection. CoDE is trained via contrastive learning by additionally enforcing global-local similarities. To sustain the training of our model, we generate a comprehensive dataset that focuses on images generated by diffusion models and encompasses a collection of 9.2 million images produced by using four different generators. Experimental results demonstrate that CoDE achieves state-of-the-art accuracy on the newly collected dataset, while also showing excellent generalization capabilities to unseen image generators. Our source code, trained models, and collected dataset are publicly available at: https://github.com/aimagelab/CoDE.