Generalizable Facial Expression Recognition
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
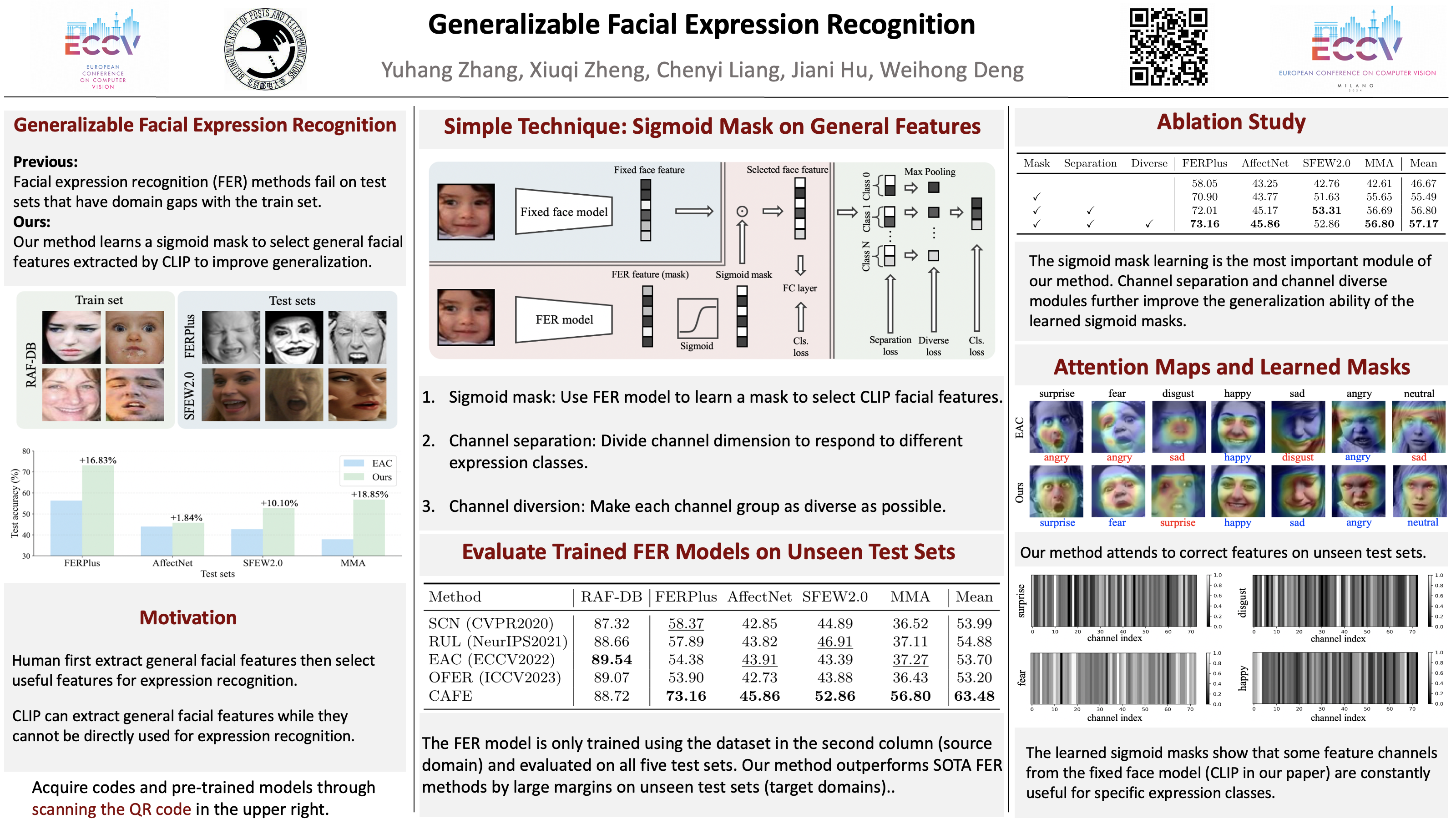
SOTA facial expression recognition (FER) methods fail on test sets that have domain gaps with the train set. Recent domain adaptation FER methods need to acquire labeled or unlabeled samples of target domains to fine-tune the FER model, which might be infeasible in real-world deployment. In this paper, we aim to improve the zero-shot generalization ability of FER methods on different unseen test sets using only one train set. Inspired by how humans first detect faces and then select expression features, we propose a novel FER pipeline to extract expression-related features from any given face images. Our method is based on the generalizable face features extracted by large models like CLIP. However, it is non-trivial to adapt the general features of CLIP for specific tasks like FER. To preserve the generalization ability of CLIP and the high precision of the FER model, we design a novel approach that learns sigmoid masks based on the fixed CLIP face features to extract expression features. To further improve the generalization ability on unseen test sets, we separate the channels of the learned masked features according to the expression classes to directly generate logits and avoid using the FC layer to reduce overfitting. We also introduce a channel-diverse loss to make the learned masks separated. Extensive experiments on five different FER datasets verify that our method outperforms SOTA FER methods by large margins. Code is available in the Supp. material.