View Selection for 3D Captioning via Diffusion Ranking
{kind=link}
Abstract
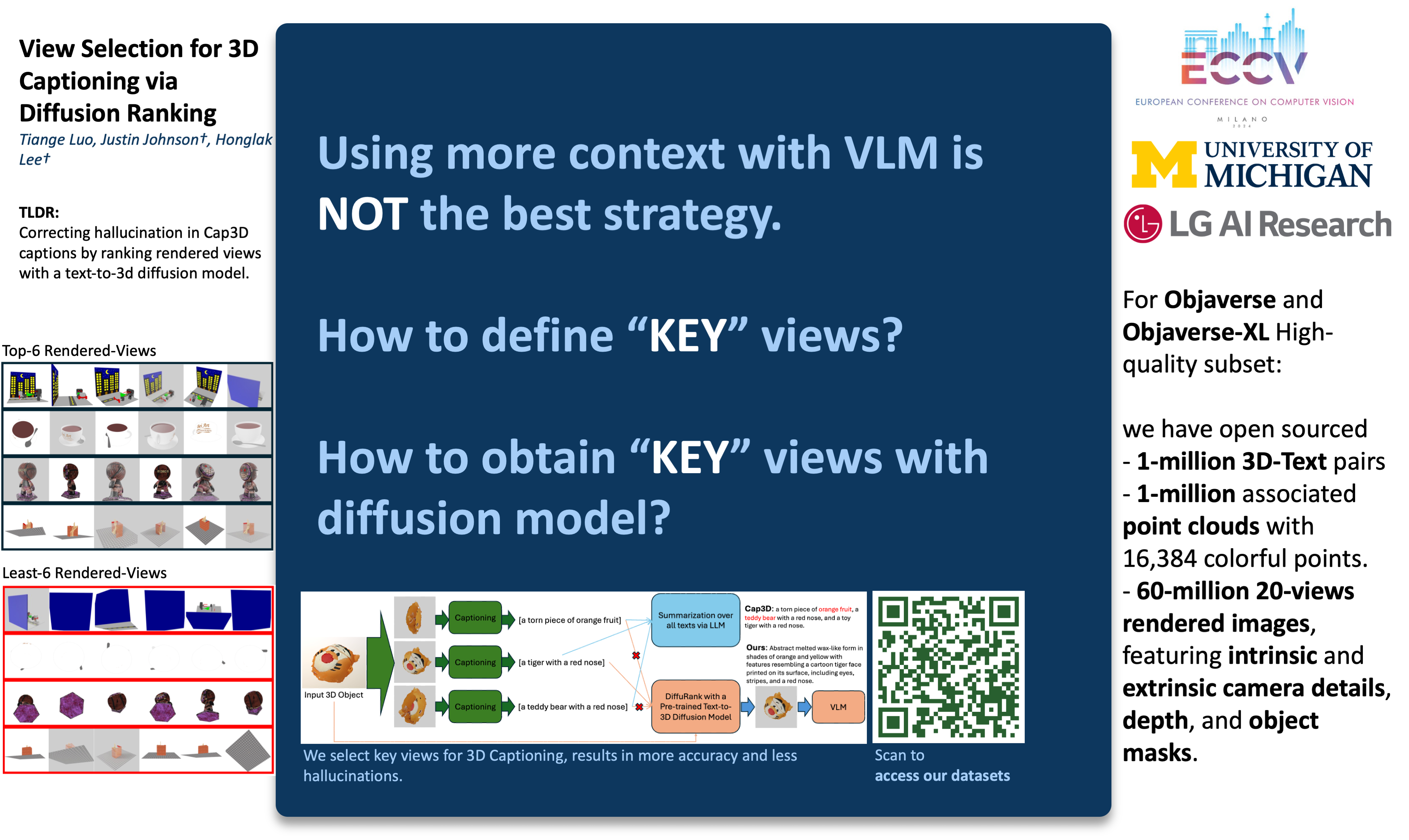
This paper explores the issue of hallucination in 3D object captioning, with a focus on Cap3D~\cite{luo2023scalable} method, which translates 3D objects into 2D views for captioning using pre-trained models. We pinpoint a major challenge: certain rendered views of 3D objects are atypical, deviating from the training data of standard image captioning models and causing errors. To tackle this, we present DiffuRank, a method that leverages a pre-trained text-to-3D model to assess the correlation between 3D objects and their 2D rendered views. This process improves caption accuracy and details by prioritizing views that are more representative of the object's characteristics. By combining it with GPT4-Vision, we mitigates caption hallucination, enabling the correction of 200k captions in the Cap3D dataset and extending it to 1 million captions across Objaverse and Objaverse-XL datasets. Additionally, we showcase the adaptability of DiffuRank by applying it to pre-trained text-to-image models for Visual Question Answering task, where it outperforms CLIP model.