HVCLIP: High-dimensional Vector in CLIP for Unsupervised Domain Adaptation
 Strong Double Blind
Strong Double Blind
{kind=link}
Abstract
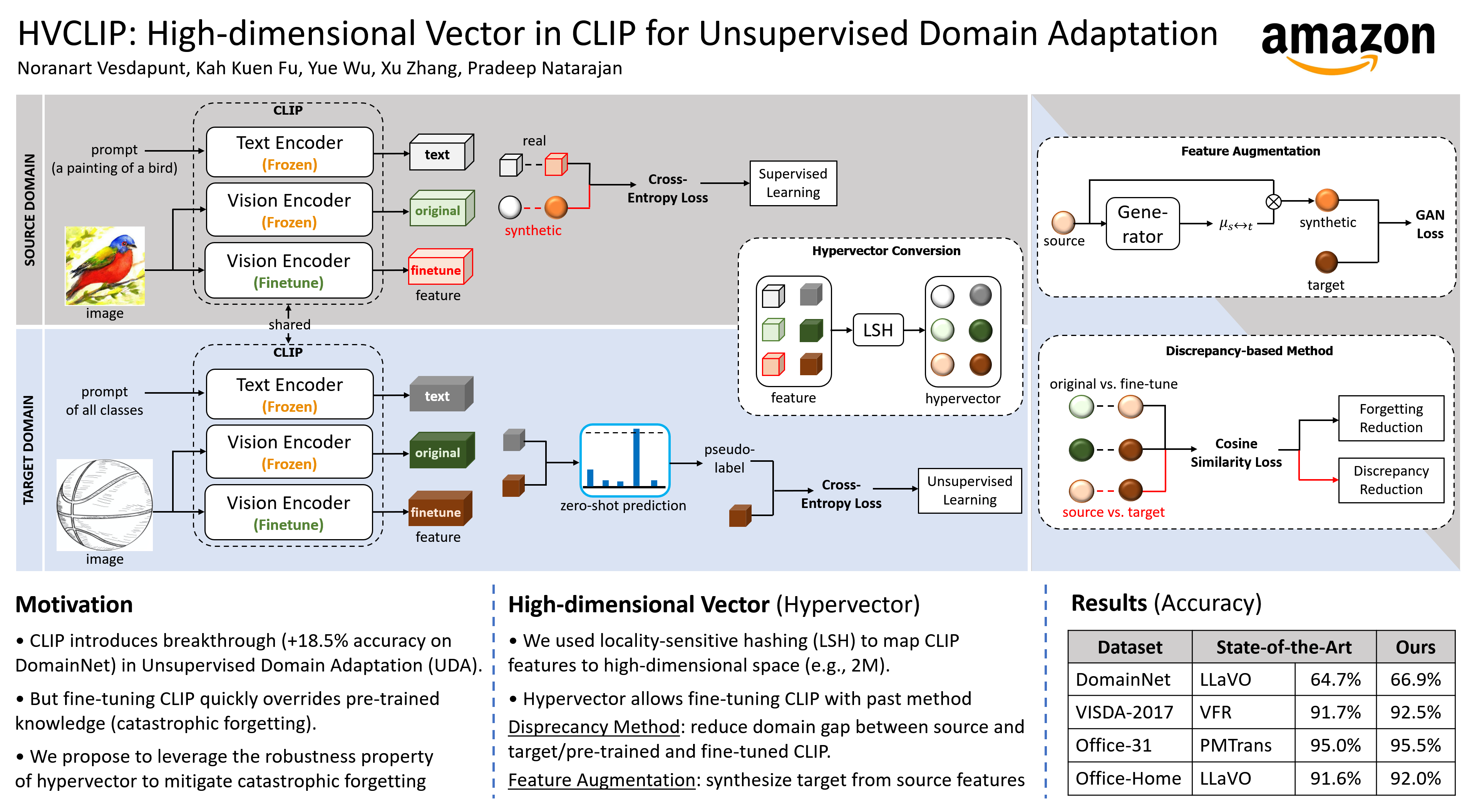
Recent advancement in the large-scale pre-training model (such as CLIP) has significantly improved unsupervised domain adaptation (UDA) by leveraging the pre-trained knowledge to bridge the source and target domain gap. Catastrophic forgetting is the main challenge of CLIP in UDA where the traditional fine-tuning to adjust CLIP on a target domain can quickly override CLIP's pre-trained knowledge. To address the above issue, we propose to convert CLIP's features into high-dimensional vector (hypervector) space to utilize the robustness property of hypervector to mitigate catastrophic forgetting. We first study the feature dimension size in the hypervector space to empirically find the dimension threshold that allows enough feature patterns to be redundant to avoid excessive training (thus mitigating catastrophic forgetting). To further utilize the robustness of hypervector, we propose Discrepancy Reduction to reduce the domain shift between source and target domains, and Feature Augmentation to synthesize labeled target domain features from source domain features. We achieved the best results on four public UDA datasets, and we show the generalization of our method to other applications (few-shot learning, continual learning) and the model-agnostic property of our method across vision-language and vision backbones.